
Einführung in Cloud-, Fog- und Edge-Computing
03.12.2021
Abstract
Im Rahmen des Vorlesungsmoduls Advanced Manufacturing (kurz: AMAN) des Masterstudiengangs Wirtschaftsingenieurwesens an der Hochschule für angewandte Wissenschaften Würzburg-Schweinfurt werden von den Studierenden Blogartikel zu verschiedenen Themen verfasst. Dieser Artikel liefert eine Einführung in verschiedene Computing-Modelle. Konkret handelt es sich hierbei um Cloud-, Fog- und Edge-Computing. Diese Modelle werden im Folgenden zunächst aus theoretischer Sicht näher definiert und voneinander abgrenzt. Anschließend wird anhand einer real existierenden und in der Produktion eingesetzten Fräsmaschine ein Einblick in die Praxis gewährt. Dieses Anwendungseispiel wird in die hier behandelten Computing-Modelle eingestuft.
Keywords: Computing Modelle, Cloud-Computing, Fog-Computing, Edge-Computing, Anwendungsbeispiel
Einleitung
Die Größe der globalen Datensphäre soll gemäß eines IDC White Papers namens The Digitization of the World – From Edge to Core, das in Zusammenarbeit mit den Storage- und Daten-Experten Seagate verfasst wurde, von 23 Zettabyte im Jahre 2017 auf 175 Zettabyte im Jahr 2025 steigen (Reinsel et al. 2018; Martins und Kobylinska 2019). Das sind umgerechnet 175.000.000.000.000 (= 175 Billionen) Gigabyte (andere Quellen, Shi et al. (2016), sprechen gar von 500 Zettabytes).
Gleichzeitig nimmt der Anteil an Echtzeitdaten an der globalen Datensphäre exponentiell auf ca. 30% zu (vgl. nachfolgende Abbildung 1), womit auf eine steigende Echtzeit-Relevanz der Daten geschlossen werden kann. Ein wesentlicher Treiber von Echtzeitdaten ist dabei das vielzitierte Internet der Dinge (engl. Internet of Things – kurz: IoT). (Reinsel et al. 2018; Martins und Kobylinska 2019)
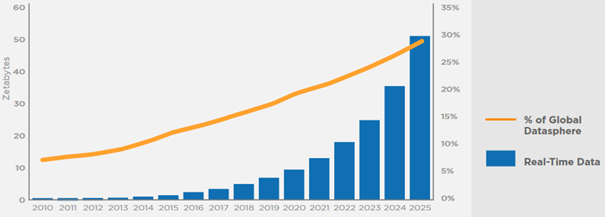
Abbildung 1: Anteil von Echtzeitdaten an der globalen Datensphäre (Quelle: Reinsel et al. (2018))
Diese Kombination aus steigender Datenmenge sowie dem Bedarf an geringen Latenzzeiten (= geringe Verzögerungs- oder Reaktionszeiten) erfordert andere bzw. weitere Computing-Modelle, als z.B. Cloud-Computing (Martins und Kobylinska 2019; Demakis Technologies 2020). Eine vielversprechende Herangehensweise stellt in diesem Kontext das sogenannte Edge Computing dar (Demakis Technologies 2020).
Was sich hinter dem Thema Edge-Computing verbirgt, wie sich dieses von anderen Computing-Modellen (z.B. Cloud- und Fog-Computing) unterscheidet und wie Computing-Modelle in der Praxis aussehen können, wird in den anschließenden Kapiteln erläutert.
Unterschiede zwischen Cloud-, Fog- und Edge-Computing
Bevor das bereits erwähnte Edge-Computing detaillierter erläutert wird, ist es hilfreich dieses von anderen Computing-Modellen, wie Cloud- und Fog-Computing, abzugrenzen. Eine diesbezügliche Hilfestellung liefert nachfolgende Abbildung 2 und die in den Kapiteln 2.1 und 2.2 folgenden Erläuterungen.

Abbildung 2: Unterschiede zwischen Cloud-, Fog- und Edge-Computing (Quelle: Ulmen (2019))
Cloud- und Fog-Computing
Gemäß Linux Foundation (2019) kann Cloud-Computing wie folgt definiert werden:
„A system to provide on-demand access to a shared pool of computing resources, including network, storage, and computation services. Typically utilizes a small number of large centralized data centers and regional data centers today.” (Linux Foundation 2019)
Cloud-Computing ist somit, vereinfacht ausgedrückt, die Bereitstellung von Computing-Services (d.h. Servern, Datenbanken, Speicher, etc.) über das Internet, d.h. einer Wolke (engl. Cloud) (Microsoft 2021).
Konkret kann bedarfsorientiert Hardware (Infrastructure as a Service, kurz: IaaS), eine Plattform (Platform as a Service, kurz: PaaS) oder eine vorkonfigurierte Software (Software as a Service, kurz: SaaS) gemietet werden. Cloud-Computing bietet dabei skalierbare Performance und Speichermöglichkeiten und ermöglicht zudem eine Erreichbarkeit losgelöst vom Endgerät bzw. Standort. An dieser Stelle liegt jedoch auch ein mögliches Problem, da die ggf. im Rahmen des Cloud-Computings entstehenden langen Wege zu einer hohen Latenz führen können. (Ulmen 2019)
Hier setzt z.B. das Fog-Computing an. Sofern die Cloud eine zu große Entfernung zu den Endgeräten aufweist, muss die Cloud im übertragenen Sinne zu den Endgeräten gebracht werden. Metaphorisch wird in diesem Zusammenhang die Wolke näher zu den Geräten und somit der Erde gebracht, weshalb diese zum Nebel (engl. Fog) wird. (Ulmen 2019)
Für Fog-Computing hat die Linux Foundation (2019) ebenfalls eine Definition formuliert, die die zuvor beschriebene Metapher bestätigt:
„A distributed computing concept where compute and data storage resource, as well as applications and their data, are positioned in the most optimal place between the user and Cloud with the goal of improving performance and redundancy. Fog computing workloads may be run across the gradient of compute and data storage resource from Cloud to the infrastructure edge. The term fog computing was originally coined by Cisco. Can utilize centralized, regional and edge data centers.” (Linux Foundation 2019)
Fog-Computing kann daher als Architekturmodell zur lokalen Datenvorverarbeitung beschrieben werden. Hierfür wird eine zusätzliche Hierarchie-Ebene zwischen datenproduzierenden Endgeräten und der Cloud aufgebaut. Diese Fog-Ebene ist dem lokalen Netz zuzuordnen, weist jedoch cloud-ähnliche Strukturen auf. Sie bringt die Cloud somit näher zu den Endgeräten. Für die Zwischenebene werden sogenannte Fog-Nodes (z.B. Router, Kameras, Notebooks, Gateways, Server, etc.) aufgebaut. Diese Nodes bilden eine Art lokale Cloud. (Ulmen 2019)
Edge-Computing
Unter Berücksichtigung von Abbildung 2 handelt es sich bei Edge-Computing um ein Computing-Modell, das noch näher oder sogar im Endgeräte (d.h. am äußersten Rand (engl. Edge) des Netzwerks) stattfindet und die Endgeräte selbst zur Verarbeitung der Daten beitragen (Ulmen 2019). Die bereits erwähnte und im Kontext des Cloud-Computings ggf. zu hohe Entfernung wird somit aufgrund des einleitend angedeuteten ansteigenden Datenvolumens bzw. der wachsenden Echtzeitrelevanz im Sinne einer geringen Latenzzeit weiter reduziert (Martins und Kobylinska 2019).
Die Linux Foundation (2019) definiert Edge-Computing in ihrem Glossar folgendermaßen:
„The delivery of computing capabilities to the logical extremes of a network in order to improve the performance, operating cost and reliability of applications and services. By shortening the distance between devices and the cloud resources that serve them, and also reducing network hops, edge computing mitigates the latency and bandwidth constraints of today’s Internet, ushering in new classes of applications. In practical terms, this means distributing new resources and software stacks along the path between today’s centralized data centers and the increasingly large number of devices in the field, concentrated, in particular, but not exclusively, in close proximity to the last mile network, on both the infrastructure and device sides.” (Linux Foundation 2019)
Zudem lässt sich Edge-Computing am besten anhand der beiden folgenden Abbildung 3 und Abbildung 4 erläutern. Wie aus Abbildung 3 ersichtlich ist, ist auf der X-Achse (=Hierarchy Levels) des Referenzarchitekturmodells Edge-Computing 4.0 (RAMEC 4.0) die Positionierung der Edge(-Art) von Product bis Cloud aufgetragen. Auf der Y-Achse (= vertikale Achse) werden hingegen die Kernfunktionen eines Edge-Knotens in Schichten beschrieben, die für eine Anwendung von Edge-Computing benötigt werden. Die Cross-Layer Concerns (=Z-Achse) betrachtet Punkte, wie Sicherheit, Echtzeitfähigkeit, Beschleunigung und Management, die auf den jeweiligen Ebenen das Modells unterschiedlich zu behandeln sind. In diesem Artikel liegt das Hauptaugenmerk auf der X-Achse. (Willner 2019, 2020; Willner und Gowtham 2020)
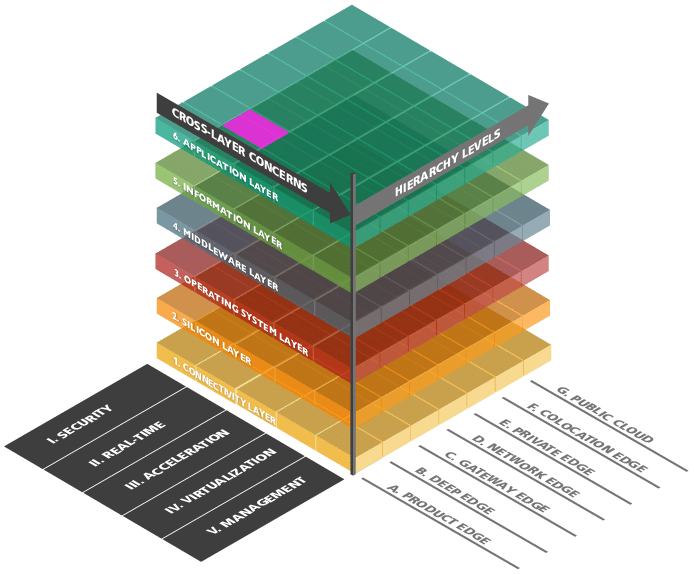
Abbildung 3: Referenzarchitekturmodell Edge-Computing 4.0 (RAMEC 4.0) (Quelle: (Willner und Gowtham 2020))
Die X-Achse aus Abbildung 3 wird in Abbildung 4 detaillierter illustriert. Es werden die einzelnen Edge-Computing-Prozesse aufzeigt und spezifisch zu den einzelnen hierarchischen Leveln beschrieben.
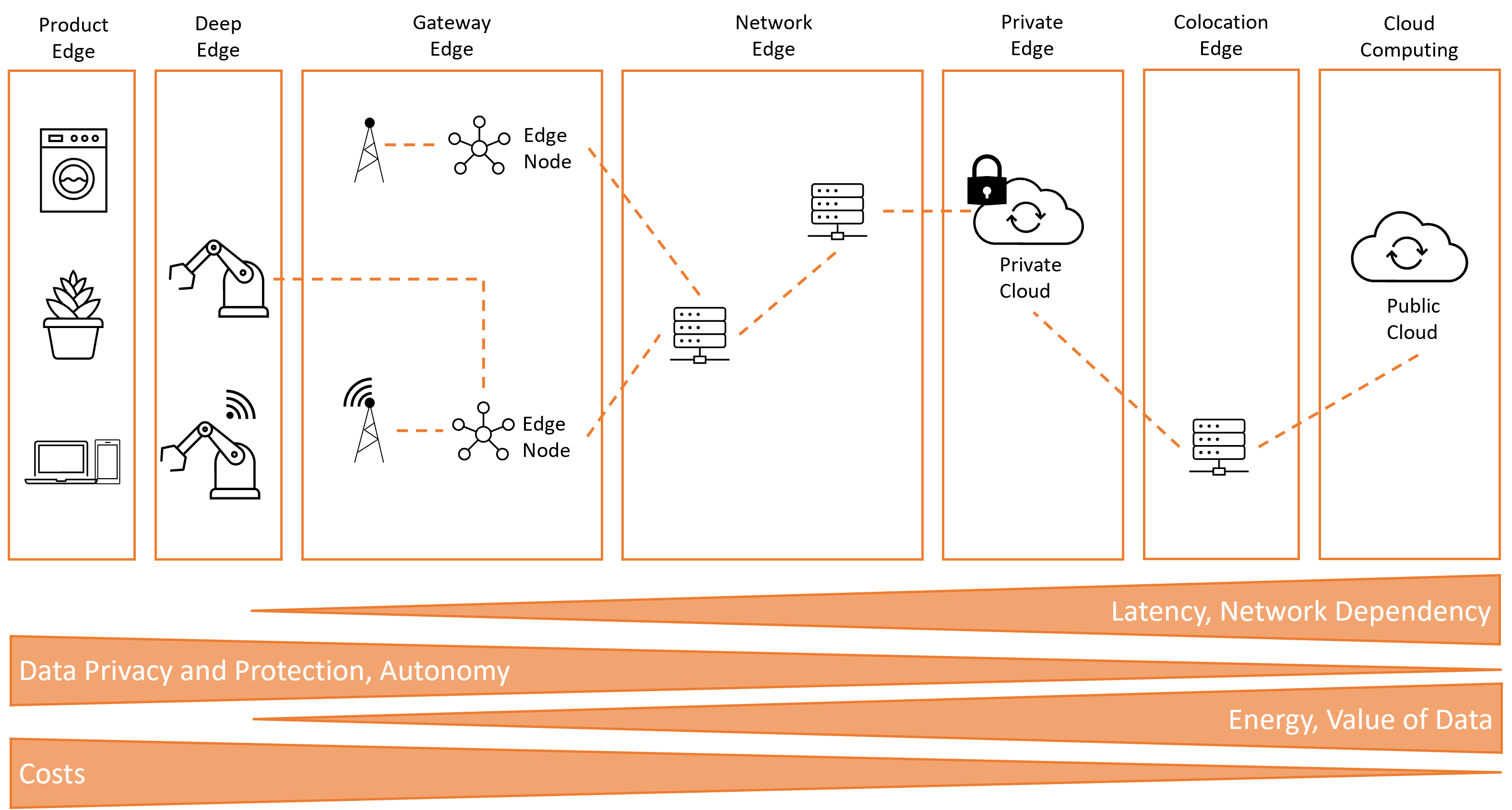
Abbildung 4: Spektrum der Edge-Computing-Begriffe und -Positionierungen (Quelle: Eigene Darstellung in Anlehnung an Willner (2019))
Die Product Edge befindet sich direkt auf dem Produkt. Bekannte Beispiele hierfür sind Handys oder Assistenzsysteme wie Amazon-Alexa, der Google Sprachassistent oder Siri von Apple. Weitere Beispiele sind außerdem Virtual und Augmented Reality, autonomes Fahren, Smart Cities oder Smart Home (Shaw 2021). Im industriellen Umfeld sind dies intelligente Maschinen, die z.B. selbst Wartungsintervalle optimieren oder im Bereich Smart Packaging das Verfolgen von Produkten über GPS-Koordinaten. Oftmals werden in diesem Zusammenhang auch intelligente Produkte angesprochen, die beim Eintreffen in die Fabrik automatisch den Fertigungsprozess anstoßen bzw. später selbst steuern. (Willner 2019)
Unter Deep Edge wird die Integration von Cloud-Computing direkt in den Produktionsanlagen verstanden. Hierbei kann die Produktionsanlage direkt mit dem Produkt kommunizieren und den Fertigungsprozess flexibel gestalten. Die Abdeckung reicht von Losgröße eins bis zur Massenproduktion.
Der Hauptanwendungsfall ist die Gateway Edge. Dies ist auf die Historie in der Produktion zurückzuführen, da hier teilweise noch Maschinen im Einsatz sind, die nicht durch modernere Versionen ersetzt werden können bzw. schlichtweg nicht ersetzt wurden. Somit liegt dieses Level so nahe wie möglich an der Maschine, um trotzdem eine Kommunikation gewährleisten zu können. Diese Kommunikationsaufgabe wird oftmals durch zusätzliche moderne SPS-Varianten (=speicherprogrammierbare Steuerungen) abgedeckt. (Willner 2019)
In der Network Edge sind viele verschiedene Knoten lokalisiert und jeder von ihnen stellt einen potenziellen Edge-Knoten dar. Somit kann dies z.B. ein Switch sein, der genügend Ressourcen bereitstellen kann, um Anwendungen oder Dienste ausführen zu können. (Willner 2019)
Die Private Edge kann mit einer privaten Cloud gleichgesetzt werden. Das Ende der topologischen Kante ist hierbei das Ende der administrativen Domäne, also an dem Ort, an dem der eigene Einflussbereich endet. (Willner und Gowtham 2020)
Eine entscheidende Rolle spielt zudem die Colocation Edge. Die Herausforderung hierbei besteht darin kleine Rechenzentren topologisch so anzuordnen, dass z.B. geringe Latenzen im Bereich von 1 ms für bestimmte 5G-Anwendungen realisiert werden können. (Willner 2019)
Vor- und Nachteile von Edge-Computing
Nachdem nun Edge-Computing vorgestellt wurde, fasst Tabelle 1 noch einmal wesentliche Vor- und Nachteile dieses Computing-Modells zusammen (vgl. hierzu auch den unteren Teil der Abbildung 4).
| Vorteile | Nachteile |
| Daten-Souveränität: Die Übermittlung großer Datenmengen ist neben der technischen Verarbeitung auch eine Herausforderung bzgl. Datenschutz, Datensicherheit etc. Bei Edge-Computing verbleiben die Daten in der Nähe der Quelle sowie innerhalb der Grenzen der geltenden Datengesetze. So werden Rohdaten lokal verarbeitet und sensible Daten gesichert, bevor diese anschließend an das sich möglicherweise im Ausland befindliche primäre Zentrum gesendet werden. | Bewusster Rohdatenverlust: Durch das Verarbeiten der Daten direkt auf dem Edge Gerät, werden nur die Analysedaten weitergeschickt. Die Rohdaten werden gelöscht. Eine mögliche folge hiervon könnte der Verlust von neuen Erkenntnissen sein. |
| Autonomie: An Standorten mit unzuverlässiger Verbindung (z.B. auf See, in Wüsten, etc.) ist Edge-Computing hilfreich. Unter solchen Rahmenbedingungen wird durch Edge Computing die Arbeit vor Ort erledigt und gespeichert. Sobald die Verbindung wieder hergestellt ist, werden die Daten an die Zentrale übertragen. Des Weiteren kann die Menge der zu übertragenden Informationen erheblich reduziert werden, wenn die Daten lokal verarbeitet werden. | Hardware: In der Praxis bzw. der Hardware, die aktuell noch im Einsatz ist, stellt sich das Problem dar, das Edge-Computing nicht auf jedes Gerät zwischen Edge-Geräte und der Cloud installiert werden kann. Denn die aktuelle Hardware ist leistungstechnisch nicht dafür ausgelegt Datenverarbeitung zu betreiben. |
| Sicherheit: Edge-Computing trägt auch zu einer weiteren Ebene der Datensicherheit bei. So können die entsprechenden Daten auf dem Weg zurück in die Cloud durch Verschlüsselung geschützt werden. Außerdem kann die Edge-Bereitstellung auch vor Hackerangriffen und bösartigen Aktivitäten geschützt werden. | Komplexität der Architektur: Die Edge-Computing Architektur setzt sich aus vielen Geräten von unterschiedlichen Herstellern zusammen. Dabei können Schnittstellenprobleme auftreten oder Kompatibilitätsprobleme beim Austausch von Protokollen. Diese vielen Geräte haben einen deutlich höheren Wartungs- und Administrationsaufwand als zentralisierte Rechenzentren. |
| Latenz: Durch die direkte Datenverarbeitung auf den Geräten oder einem nahegelegenen Edge-Node, kann seine geringe Latenz sichergestellt werden. Denn die Daten müssen nicht bis zur Cloud und wieder zurück auf das entsprechende Gerät. Hierdurch können ebenfalls Kosten eingespart werden, da der Ausbau der Bandbreite in die Cloud nicht mehr von äußerster Relevanz ist. | Sicherheitskonzepte: Wie in den Vorteilen beschrieben, steigt die Sicherheit durch die lokale Datenhaltung. Dies kann aber nur gewährleistet werden, wenn die dezentralen Geräte ein passendes Sicherheitskonzept haben. Zudem ist der Aufwand zu Entwicklung dieser Sicherheitskonzepte deutlich höher, da durch die Heterogenität und Vielzahl von unterschiedlichen Geräten für jedes Gerät ein Sicherheitskonzept umgesetzt werden muss. |
Präzisere Abgrenzung zwischen Fog- und Edge Computing
Zum Abschluss des Kapitels 2 ist es sinnvoll, Fog- und Edge-Computing noch einmal präziser voneinander abzugrenzen. Hintergrund hierfür ist, dass diese oftmals auch als Synonym zueinander verwendet werden (Varghese et al. 2016; Ulmen 2019). Auch die vorherigen Erläuterungen zeigen, dass die Übergänge in diesem Zusammenhang fließend sind. Bei genauerer Betrachtung können diese jedoch unterschieden werden (Ulmen 2019; Demakis 2021).
Entsprechende Unterschiede können aus nachfolgender Tabelle 2 entnommen werden.
| Fog-Computing | Edge-Computing |
| Fog-Computing kann als Oberbegriff für die Datenvorverarbeitung in einem lokalen Netzwerk verwendet werden. | Edge-Computing ist in diesem Zusammenhang eine spezielle Form der Datenvorverarbeitung. |
| Den Fog Nodes sind alle in der Domäne existierenden Geräte bekannt. Bei Analysen ist ein Zugriff auf die anderen Geräte sowie eine Kommunikation mit diesen möglich. Fog Nodes können weiterhin Entscheidungen treffen und geringe Datenmengen zwischenspeichern. | Im Edge werden dagegen nur einfache Aufgaben, wie z.B. das Filtern und Zusammenfassen von Daten, ausgeführt. Edge-Geräte besitzen keine Kenntnis voneinander und kommunizieren folglich auch nicht gegenseitig. |
| Bei Fog-Nodes handelt es sich oftmals um bereits im Netzwerk vorhandene Geräte, die sich in einer Ebene zwischen den Endgeräten und der Cloud befinden. Die Rechenleistung der Fog-Nodes wird für Analysen verwendet. Fog Computing verlagert die gesamte Intelligenz auf die LAN-Ebene der Netzwerkstruktur. | Edge-Computing findet hingegen meist direkt am oder sogar im Endgerät statt, sodass die Intelligenz näher am Gerät angesiedelt ist. |
Anwendungsbeispiel zu Computing-Modellen
Nachdem in den vorherigen Kapiteln die Themen Cloud-, Fog- und Edge-Computing aus theoretischer Sicht beleuchtet wurden, wird nun ein Anwendungsbeispiel in diesem Zusammenhang vorgestellt. Dieses Beispiel wird in Anlehnung an die bereits vorgestellten Schichten (vgl. Abbildung 4, Kapitel 2.2) in nachfolgender Abbildung 5 skizziert.

Abbildung 5: Struktur des Anwendungsbeispiels (Quelle: Eigene Darstellung unter Verwendung von Definitionen aus Willner (2019))
Konkret wird eine in der Realität eingesetzte Fräsmaschine über einen Heidenhain-Agent auf einem Windows-IndustriePC (kurz: IPC) angebunden. Die Datenabfrage per MQTT-Protokoll wird hierbei über die Anwendung Cybus realisiert, welche wiederum auf einer linuxbasierten Virtuellen Maschine (kurz: VM) gehostet ist. Hierbei bietet Cybus für das Extrahieren, Transformieren und Laden der Daten (engl. Extract, Transform und Load – kurz: ETL) eine Node-Red-Oberfläche, um die Daten in eine Datenbank (hier: Influx) zu schreiben. Die abgefragten Daten werden dann via Grafana visualisiert.
In Abbildung 6 wird diesbezüglich ein beispielhafter Node-Red Flow aufgezeigt.
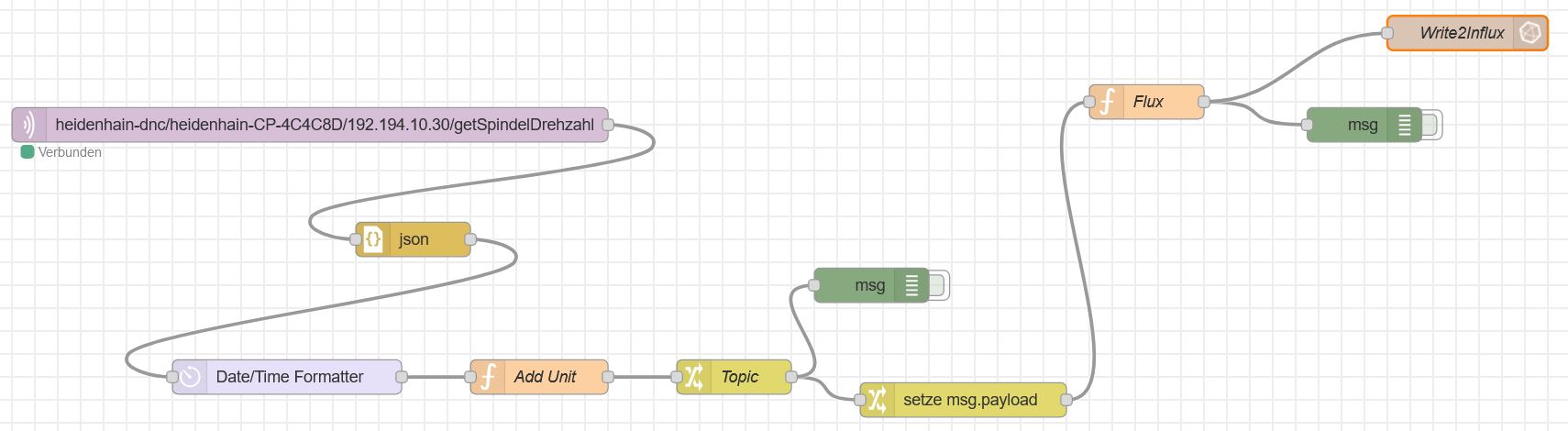
Abbildung 6: Node-Red Flow – Übertragung von Maschinendaten in Datenbank (Quelle: Eigene Darstellung)
Zunächst werden die Daten des WindowsIPC (z.B. die Spindeldrehzahl der Fräsmaschine) über ein MQTT-Topic abgefragt und in ein JSON-Format transformiert. Anschließend werden die Daten in dem Node-Red Flow mit einem aktuellen Zeitstempel und der entsprechenden Einheit (z.B. 1/min) versehen. In den darauffolgenden Schritten wird der Payload der Daten im JSON-Format für das Senden an die Datenbank präpariert. Abschließend werden die Daten per influxdb out Node in den entsprechend angegebenen Bucket der Influx-Datenbank geschrieben.
Wie in nachfolgender Abbildung 7 schrittweise dargestellt, kann nun in der Influx-Datenbank der Code für den Datenabgriff generiert werden.
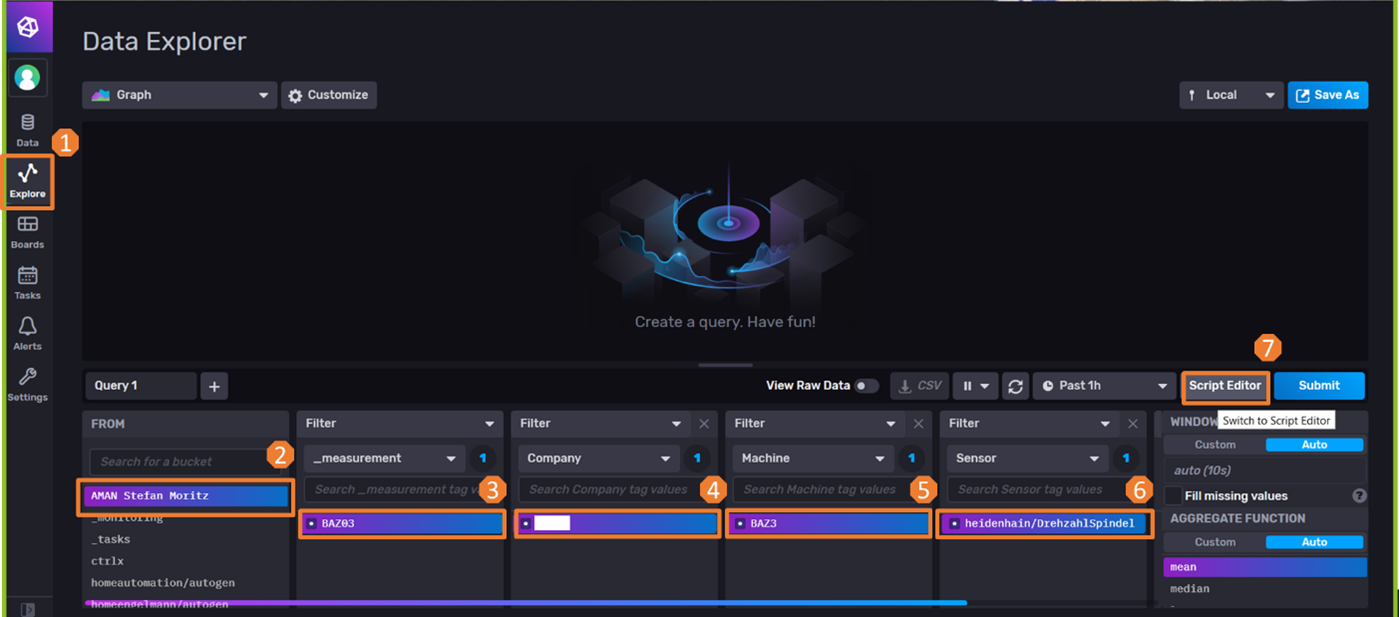
Abbildung 7: Generierung Code für Grafana (Quelle: Eigene Darstellung)
Der in Abbildung 7 generierte Code kann dann in Grafana im Zuge der Erstellung eines Dashboards bzw. Panels und der Auswahl der zugehörigen Datenquelle (=Influx Bucket) eingefügt werden.

Abbildung 8: Generierung des Dashboards in Grafana (Quelle: Eigene Darstellung)
Nach der Speicherung bzw. dem Drücken des Buttons Apply werden die Spindeldrehzahldaten in Form einer Zeitreihe visualisiert (vgl. Abbildung 9).
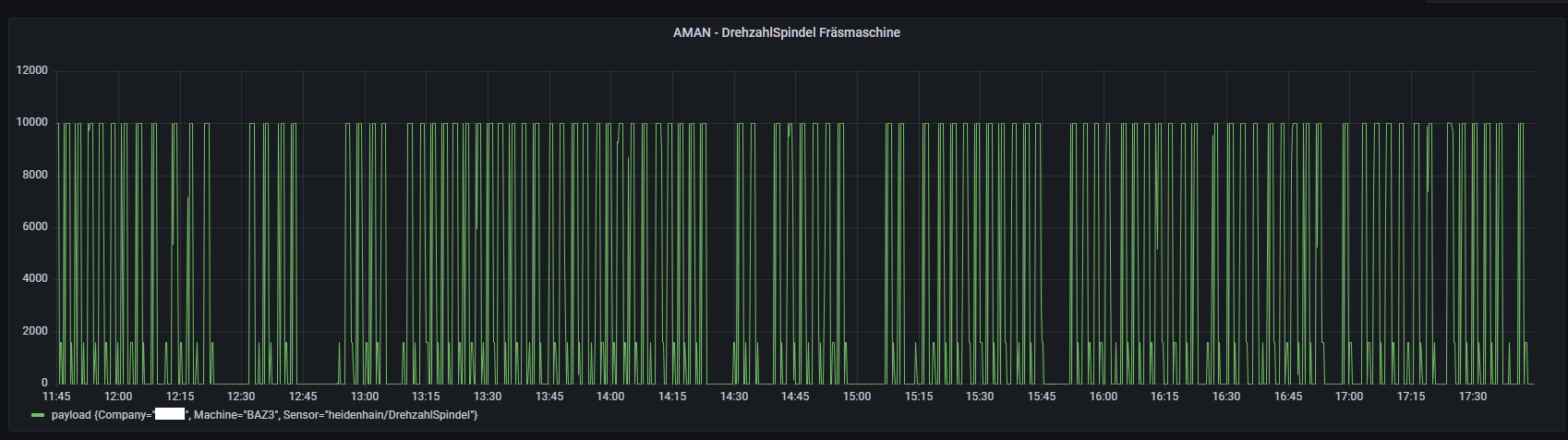
Abbildung 9: Beispielhaftes Panel der Drehzahldaten der Fräsmaschine (Quelle: Eigene Darstellung)
Abschließend kann im Hinblick auf das vorgestellte Anwendungsbeispiel und unter Bezugnahme auf die theoretischen Ausführungen in Kapitel 2 festgehalten werden, dass das Beispiel Ansätze des Edge-Computings und des Fog-Computings widerspiegelt. Während, wie in Abbildung 10 dargestellt, die Fräsmaschine, der WindowsIPC und das Cybussysteme Elemente des Edge-Computings enthält (z.B. das Hinzufügen von Zeitstempeln an den Maschinendaten (Slama et al. 2021, S. 40)), stellen die Influx-Datenbank und Grafana Komponenten des Fog-Computings dar. Denn diese beiden Komponenten werden im lokalen Netzwerk betrieben und sind somit in der Private Edge anzusiedeln.
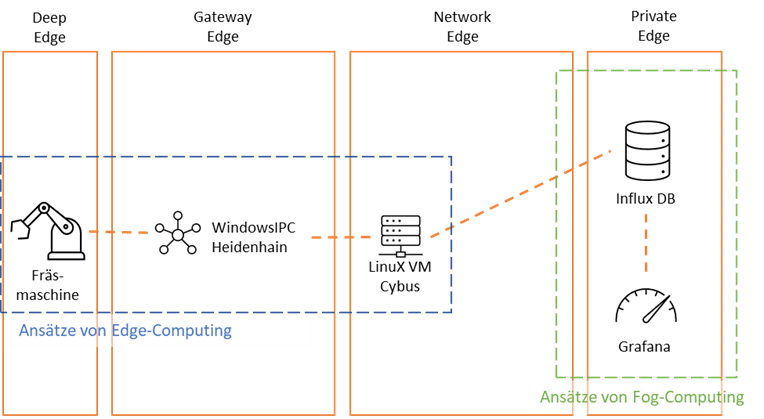
Abbildung 10: Vergleich Edge-/Fog-Computing im Anwendungsbeispiel (Quelle Eigene Darstellung)
Fazit
Zusammenfassend kann festgehalten werden, dass Cloud-, Fog- oder Edge- Computing sich nicht gegenseitig ausschließen oder eine Technologie mehr Vorteile besitzt als die andere. Vielmehr können diese, wie auch das Anwendungsbeispiel bzgl. der Fräsmaschine gezeigt hat, sehr gut miteinander kombiniert werden. (Ulmen 2019; Demakis 2021)
Beispielsweise können anfallende Daten per Edge-Computing gefiltert, aggregiert und anschließend an den nächstgelegenen Fog-Node gesendet werden. Die Fog-Computing-Zwischenebene führt dann erste Datenanalysen durch. Sofern Aufgaben existieren, welche z.B. eine gewisse Komplexität aufweisen, werden diese in die Cloud weitergeleitet. Daraus wird deutlich, dass die Cloud auch zukünftig eine wichtige Struktur ist und nicht von anderen Computing-Modellen abgelöst wird. Aufgrund der Tatsache, dass die Cloud bedeutend mehr Ressourcen bietet, ist sie für bestimmte Anwendungsfälle passender als Edge- oder Fog-Computing. (Ulmen 2019)
Für den Fall, dass eine Kombination wenig förderlich ist, muss sich die Frage gestellt werden, wo die Daten gebraucht werden und wie lange die Bereitstellung benötigen darf. Bei Anwendungsfällen, die eine Echtzeitrelevanz von wenigen Sekunden vorweisen, sollte auf Edge-Computing gesetzt werden, um die Latenz so klein wie möglich zu halten. Das passende Beispiel hierfür ist die Gesichtserkennung auf einem Smartphone. Möchten Benutzer:innen das Handy über die Gesichtserkennung entsperren, soll eine lange Wartezeit hierfür möglichst ausgeschlossen werden. Im Rahmend es Cloud-Computings würden die Gesichtserkennungsdaten zunächst jedoch erst an die Cloud geschickt und dort verarbeitet werden. Anschließend würde die Rückmeldung an das Handy geschickt werden, um das Handy letztendlich zu entsperren. Dies würde keine benutzerfreundliche Entsperrung darstellen. Aus diesem Grund wird diese Anwendung in der Praxis oftmals per Edge-Computing realisiert. (Demakis Technologies 2020)
Literaturverzeichnis
Demakis, Roxanne (2021): Edge Computing vs Fog Computing. Hg. v. Demakis Technologies. Online verfügbar unter https://demakistech.com/edge-computing-vs-fog-computing/, zuletzt aktualisiert am 06.09.2021, zuletzt geprüft am 21.11.2021.
Demakis Technologies (2020): Edge Computing Vs. Cloud Computing. Online verfügbar unter https://www.youtube.com/watch?v=MBUabimpai0, zuletzt aktualisiert am 19.09.2020, zuletzt geprüft am 18.11.2021.
Linux Foundation (2019): Open Glossary of Edge Computing. Linux Foundation. Online verfügbar unter https://github.com/State-of-the-Edge/glossary/blob/master/PDFs/OpenGlossaryofEdgeComputing_2019_v2.0.pdf, zuletzt geprüft am 21.11.2021.
Luber, Stefan; Donner, Andreas (2019): Was ist Edge Computing? Hg. v. Vogel Communications Group. Online verfügbar unter https://www.ip-insider.de/was-ist-edge-computing-a-823609/, zuletzt geprüft am 27.11.2021.
Martins, Filipe; Kobylinska, Anna (2019): Was bedeutet Edge Computing? Online verfügbar unter https://www.industry-of-things.de/was-bedeutet-edge-computing-a-678225/, zuletzt aktualisiert am 25.01.2019, zuletzt geprüft am 18.11.2020.
Microsoft (2021): Was ist Cloud Computing? Leitfaden für Einsteiger. Online verfügbar unter https://azure.microsoft.com/de-de/overview/what-is-cloud-computing/, zuletzt geprüft am 21.11.2021.
Reinsel, David; Gantz, John; Rydning, John (2018): The Digitization of the World. From Edge to Core. Hg. v. International Data Corporation (IDC) und Seagate. Online verfügbar unter https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf, zuletzt geprüft am 18.11.2021.
Shaw, Keith (2021): Wie funktioniert Edge Computing? Hg. v. IDG Business Media GmbH. Online verfügbar unter https://www.computerwoche.de/a/was-ist-edge-computing,3550237, zuletzt geprüft am 27.11.2021.
Shi, Weisong; Cao, Jie; Zhang, Quan; Li, Youhuizi; Xu, Lanyu (2016): Edge Computing: Vision and Challenges. In: IEEE Internet Things J. 3 (5), S. 637–646. DOI: 10.1109/JIOT.2016.2579198.
Slama, Dirk; Rückert, Tanja; Thrun, Sebastian; Homann, Ulrich; Lasi, Heiner (2021): The AIoT Playbook. A Practitioner’s Guide to Smart, Connected Products and Solutions. Hg. v. Springer International Publishing. Online verfügbar unter https://www.aiotplaybook.org/index.php?title=The_AIoT_Playbook, zuletzt geprüft am 03.12.2021.
talend (o. J.): Edge Analytics: Die Vor- und Nachteile unmittelbarer, lokaler Erkenntnisse. Online verfügbar unter https://www.talend.com/de/resources/edge-analytics-pros-cons-immediate-local-insight/, zuletzt geprüft am 27.11.2021.
Ulmen, Tanja (2019): Fog und Edge Computing – Datenverarbeitung im IoT. Hg. v. ComConsult GmbH. Online verfügbar unter https://www.comconsult.com/fog-edge-computing-iot/, zuletzt aktualisiert am 04.05.2019, zuletzt geprüft am 21.11.2021.
Varghese, Blesson; Wang, Nan; Barbhuiya, Sakil; Kilpatrick, Peter; Nikolopoulos, Dimitrios S. (2016): Challenges and Opportunities in Edge Computing. In: IEEE (Hg.): 2016 IEEE International Conference on Smart Cloud (SmartCloud). New York, USA, 18.11.2016 – 20.11.2016. Piscataway Township, New Jersey, USA: IEEE, S. 20–26.
Willner, Alexander (2019): Industrielles Edge-Computing als neues Paradigma – Weit verteilt. In: C’t, 2019 (iX 11), S. 50–54.
Willner, Alexander (2020): Der Edge-Computing-Ansatz. Hg. v. WEKA Fachmedien GmbH. Online verfügbar unter https://www.computer-automation.de/steuerungsebene/industrie-pc/der-edge-computing-ansatz.166072/seite-6.html, zuletzt aktualisiert am 21.11.2021.
Willner, Alexander; Gowtham, Varun (2020): Toward a Reference Architecture Model for Industrial Edge Computing. In: IEEE Comm. Stand. Mag. 4 (4), S. 42–48. DOI: 10.1109/MCOMSTD.001.2000007.

Moritz Rauber
- Student im Masterstudiengang Wirtschaftsingenieurwesen

Stefan Füller
- Student im Masterstudiengang Wirtschaftsingenieurwesen

