
Die Rolle von Virtual Reality und Augmented Reality in I4.0
18.12.2021
Abstract
Sowohl Virtual Reality (VR) als auch Augmented Reality (AR) sind in den letzten Jahren ein fester Bestandteil in der Medienwelt geworden. Tatsächlich gaben einer Studie zufolge die meisten Menschen (77 %) an, VR für Computer- oder Videospiele zu nutzen. Nur 8 % gaben an, die Technologie bereits im beruflichen Kontext eingesetzt zu haben. (vgl. Statista, 2021) Tatsächlich bestehen trotz der großen Verbreitung weiterhin immer noch Unsicherheiten bezüglich der konkreten Einsatzmöglichkeiten in der Industrie (vgl. bitkom, 2021, S.9). Der folgende Eintrag soll zeigen, wie die Techniken bereits in Unternehmen verwendet werden und welches Potenzial diese für I4.0 mitbringen. Zunächst werden dafür die Begriffe Industrie 4.0 (I4.0), Virtual Reality und Augmented Reality definiert und erläutert. Danach werden beispielhaft fünf Einsatzfelder dieser Techniken in der Industrie thematisiert sowie jeweils ein Beispiel genannt, wie dieses bereits konkret in der Praxis umgesetzt wird. Abschließend soll geklärt werden, wie oft die einzelnen Methoden in den deutschen Firmen tatsächlich verwendet werden und die Vorteile von AR und VR genannt werden.
Grundlagen von I4.0
Industrie 4.0 beschreibt nach der Nutzung von Wasser und Dampfkraft (erste Revolution), der Einführung von Massenproduktion durch elektrische Energie (zweite Revolution) und der Nutzung von IT zur Animation nun die vierte industrielle Revolution (vgl. Roth, 2016, S.5). Tatsächlich existiert bis heute keine einheitliche Definition für diesen Begriff. Laut der Plattform Industrie 4.0 des Bundesministeriums für Wirtschaft und Klimaschutz bezeichnet der Begriff die intelligente Vernetzung von Maschinen und Prozessen in Unternehmen mithilfe von Informations- und Kommunikationstechnologie, wodurch Menschen, Maschinen und Produkte miteinander verknüpft werden (vgl. Plattform Industrie 4.0, 2021). Diese Definition soll auch für den folgenden Eintrag geltend sein. Kennzeichnend für I4.0 sind die vier Merkmale Individualisierung, flexible und effiziente Produktion, Integration von Stakeholdern und die Verkopplung von Produktion und Dienstleistungen (vgl. Roth, 2016, S.6).
Begriffsabgrenzung VR und AR
Der Begriff „Virtual Reality“ kann ins Deutsche mit virtueller Realität (VR) übersetzt werden und bezeichnet eine simulierte Wirklichkeit oder künstlich erschaffene Welt, in welche sich Menschen durch Hilfsmittel, wie beispielsweise einer 3D-Brille hineinversetzen können und auch damit interagieren können. Hierbei wird die Realität um den Nutzer herum komplett ausgeblendet. (vgl. Brill, 2009, S.5f)
Der Unterschied zur sogenannten „Augmented Reality“ (AR), was ins Deutsche mit erweiterter Realität übersetzt werden kann, liegt darin, dass hier ein Live Video der Realität gezeigt wird, und dazu zusätzliche virtuelle Elemente, wie beispielsweise Gegenstände in 3D eingeblendet werden, mit welchem der Benutzer interagieren kann. (vgl. Tönnis, 2010, S.1f.)
Die folgende Graphik soll die Tendenzen von AR und VR bezüglich realer und virtueller Welt visualisieren:

Einsatzfelder von VR und AR in der Industrie
Grundsätzlich ist der Einsatzbereich von AR und VR bezüglich I4.0 sehr breit gefächert. So wird das Konzept bereits in vielen verschiedenen Branchen wie der Medizin oder der Architektur angewendet. Die Einsatzgebiete lassen sich generell in Kollaboration, Assistence und Learning unterscheiden (vgl.bitkom, 2021, S.17). Im Folgenden sollen beispielhaft für einige Prozessschritte innerhalb des Wertschöpfungsprozesses Anwendungsmöglichkeiten der beiden Techniken beschreiben werden:
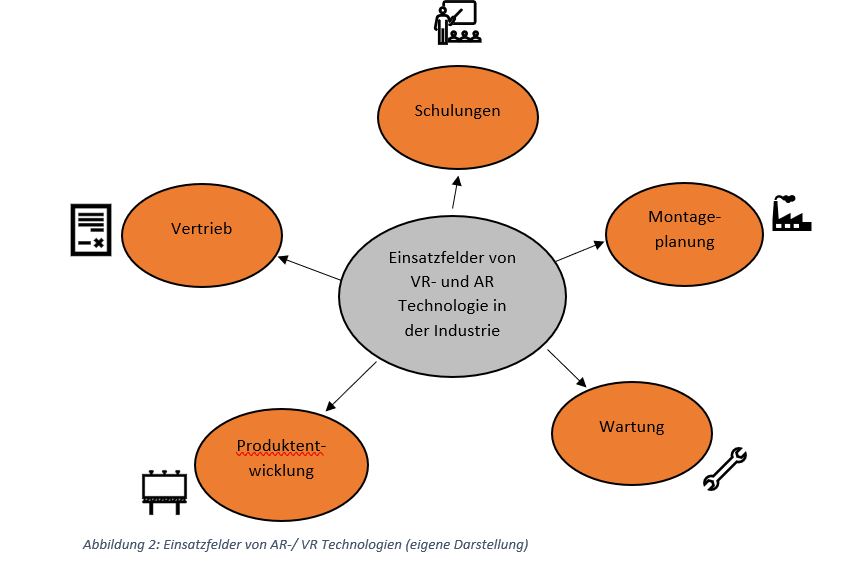
Vertrieb: Hier kann dem Kunden der digitale Zwilling des Produktes in einem hohen Detaillierungsgrad gezeigt werden, bevor die Produktion überhaupt gestartet hat. Dadurch kann dieses nach Wünschen des Kunden besser individuell angepasst und konfiguriert werden. Außerdem können durch die ausführliche Präsentation des Produktes noch unsicherer Kunden überzeugt werden. (vgl.bitkom, 2021, S.64)
Bsp.: Mitarbeiter aus dem Vertrieb beim Roboterhersteller KUKA können dem Kunden vor Ort ihre Lösungen und Vorschläge durch eine spezielle Software in VR präsentieren. (vgl. VR Dynamix GmbH, 2020)
Produktentwicklung: Zunächst können die CAD-Daten detaillierter betrachtet und im Team besprochen und verändert werden. Daneben werden Prototypen auf diese Art effizienter gestaltet, Produkte getestet und Fehler frühzeitig erkannt. Dies spart Zeit und Geld, welche normal in die Anfertigung von physischen Prototypen fließen würden. Durch die Möglichkeit der virtuellen Simulation werden die Möglichkeiten vergrößert und die Kreativität der Mitarbeiter verstärkt, da die Umsetzung schneller und leichter geht und sofort überprüft werden kann. (vgl.bitkom, 2021, S.24f.)
Bsp.: Beim Helikopter FCX-001 der Marke Bell konnte durch den Einsatz von VR Technologie die Entwicklungsdauer von normalerweise sieben Jahre auf weniger als sechs Monate reduziert werden. Dies war unter anderem möglich, da die Ingenieure über den gesamten Entwicklungsprozess hinweg das maßstabsgetreue Modell erleben konnten, anstatt mehrere Modelle zu erstellen. Dadurch war die Abstimmung leichter und das Feedback schneller einholbar. Grundsätzlich gibt die Firma an, dadurch mehrere Millionen Euro eingespart zu haben. (vgl. Everett, 2018)
Wartung: Durch AR gestützte Remote Assistance können Probleme viel schneller und effizienter von Experten gelöst werden. Indem diese das Problem aus Sicht der Mitarbeiter sehen, können sie ohne vor Ort zu sein das Problem erkennen und Lösungsvorschläge direkt in das virtuelle Blickfeld des Mitarbeiters verankern. (vgl.bitkom, 2021, S.27)
Bsp.: Die Firma Voith bietet ein Expertenteam und die passende VR Technologie an, um die Fernwartung von Industrieanlagen, ins besonders von Wasserkraftanlagen zu verbessern. Die Experten haben durch die Technik eine andere Perspektive auf das Problem und können dabei helfen, die Wartungsarbeiten zu beschleunigen, indem Mitarbeiter vor Ort mit diesen Experten interaktiv zusammenarbeiten können. (vgl. VR Dynamix GmbH, 2020)
Montageplanung: Hier kann der Montageprozess bereits im Vorfeld simuliert werden, um auch Aspekte wie die Ergonomie oder die Bedienersicherheit zu optimieren. Beispielsweise kann damit die Erreichbarkeit von Arbeitsmitteln gesichert oder die Arbeitshöhe angepasst werden. Hierdurch steigt sowohl die Produktionsgeschwindigkeit als auch die Effizienz der Mitarbeiter am Arbeitsplatz. (vgl.bitkom, 2021, S.30)
Bsp.: Das Fraunhofer-institut und der Automobilzulieferer HELLA haben zusammen ein Mixed Mock-up entwickelt. Hier wird der Arbeitsplatz zunächst aus Pappe gebaut, auf welche dann virtuelle Teile und Werkzeuge projiziert werden. Dadurch entsteht das Mixed Mock-up, bei welchem einzelne Arbeitsschritte getestet werden können. Grundsätzlich können hierdurch neue Arbeitsplätze effizienter geplant werden und die Zusammenarbeit von Entwicklern verbessert werden. (vgl. Fraunhofer, 2018)
Schulungen: Durch den Einsatz von VR-/AR-Technik kann die Einarbeitung von Mitarbeitern oder die Einführung neuer Prozesse vereinfacht werden, indem den Mitarbeitern wichtige Informationen oder Anleitungen eingeblendet werden. Weiterhin dient dies auch zum Einlernen von Azubis, da diese die Abläufe zunächst online üben können und anschließend erfahren in der Realität arbeiten können. Das zuvor erlernte theoretische Wissen kann also später in der Praxis angewendet werden. Dadurch wird das Verletzungspotential minimiert, die Störung des laufenden Betriebs vermieden und weniger Kosten verursacht. (vgl. VR Dynamix GmbH, 2020)
Bsp.: Bei Bosch werden Kfz-Mechatroniker durch eine AR-Technologie geschult, in welcher Hochvolt-Komponenten erläutert werden und Strategien zur Behebung von Fehlern an denselben erklärt werden. Nach dieser Fortbildung dürfen diese dann an Hochvolt-Komponenten arbeiten. Der Vorteil hiervon ist, dass diese zunächst in einer ungefährlichen Software geschult werden und erst danach mit den Komponenten in Berührung kommen. Weiterhin können durch die Technologie beispielsweise auch Strukturen, welche hinter der Verkleidung des Kfz liegen, gezeigt werden. (vgl. Bosch, 2018)
Nutzung in Unternehmen
Im Jahr 2019 befragte die Firma IDG Business Media GmbH 145 Unternehmen, welche VR-/AR Funktionen von diesen am meisten benutzt werden:

Diese ergab, dass die meisten Unternehmen die Techniken für Schritt-für Schritt Anleitungen, Remote Assistence und Wissenstransfer nutzen. Grundsätzlich ergibt sich aber auch, dass von den Unternehmen ganz vielfältige Funktionen aus unterschiedlichen Bereichen genutzt werden.
Vorteile und Nachteile von VR/AR
Aus der Verwendung von AR- und VR Verfahren ergeben sich nun folgende Vorteile und Nachteile, von denen einige bereits in dem vorgehenden Abschnitt genannt wurden: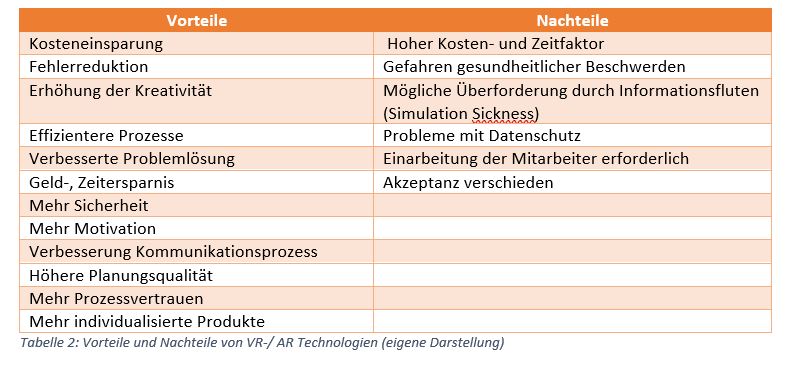
Fazit:
Bereits heute findet man VR- und AR Anwendungen in einem Großteil von Firmenbereichen und entlang der gesamten Wertschöpfungskette. Wenn man sich die Eigenschaften von Industrie4.0 vom Anfang noch einmal durchliest, stellt fest, dass diese durch den Einsatz der Techniken unterstützt werden können:
- Individualisierung
→ Bsp.: Bessere Anpassung an Kundenbedürfnisse, da das Produkt durch die Applikation schneller und besser angepasst werden kann
- Flexible und effiziente Produktion
→ Bsp.: Optimierung der Montageplanung bereits im Vorfeld
- Integration von Stakeholdern
→ Bsp.: Detaillierte Präsentation von Plänen und leichter Feedback einholbar
- Verkoppelung von Produktion und Dienstleistungen
→ Bsp.: Anbieten und Nutzung von Fernwartungen
Auch die vielfältigen Vorteile, welche aufgezeigt worden sind, zeugen vom Potential für I4.0, da sich hierdurch Wettbewerbsvorteile entwickeln können, welche wiederum zur Optimierung des Unternehmenserfolgs führen können. Grundsätzlich bedarf es für den Erfolg in I4.0 aber nicht nur diese Techniken, sondern sie sollte auch um andere Methoden, wie zum Beispiel dem Big Data Analytics ergänzt werden.
Nach Studien der IDG Business Media GmbH nutzten bereits im Jahr 2019 fast die Hälfte der Unternehmen ab 1000 Mitarbeitern AR- und VR Technologien im Produktionsbereich. Bei kleineren Unternehmen lag die Zahl bei 30 % (vgl. IDG, 2019, S.7). Tatsächlich ist davon auszugehen, dass diese Zahlen in den nächsten Jahren weiter steigen werden. Wenn die Technologien noch weiter ausgereift sind und mit mehr Leistung einhergehen, könnte damit auch die Akzeptanz steigen und der Einsatz der Technologien in der Praxis noch großflächiger zur Normalität werden.
Literaturverzeichnis
Bitkom (2021) Augmented und Virtual Reality Potenziale und praktische Anwendung immersiver Technologien. Online unter: https://www.bitkom.org/sites/default/files/2021-04/210330_lf_ar_vr.pdf (Letzter Zugriff: 18.12.2021)
Bosch (2018) Voller Durchblick bei technischen Service Trainings: Bosch schult Kfz-Mechatroniker mit innovativer Augmented Reality Technologie. Online unter: https://www.bosch-presse.de/pressportal/de/de/voller-durchblick-bei-technischen-service-trainings-bosch-schult-kfz-mechatroniker-mit-innovativer-augmented-reality-technologie-166656.html (Letzter Zugriff: 18.12.2021)
Brill, M. (2009) Virtuelle Realität. In: Virtuelle Realität. Informatik im Fokus. Springer, Berlin, Heidelberg. Online unter: https://doi.org/10.1007/978-3-540-85118-9_2 (Letzter Zugriff: 18.12.2021)
Everett, L. (2018) Bell sagt dass der neueste Hubschrauber mit VR 10-mal schneller entwickelt wurde. RoadtoVR . Online unter: https://www.roadtovr.com/bell-says-latest-helicopter-was-designed-10-times-faster-with-vr/ (Letzter Zugriff: 18.12.2021)
Fraunhofer (2018) Mit der Zukunft hantieren. Mixed Mock-Ups erleichtern die Planung von Montagearbeitsplätzen. Online unter: https://www.fraunhofer-innovisions.de/arbeitsplatz-der-zukunft/mit-der-zukunft-hantieren/ (Letzter Zugriff: 18.12.2021)
IDG (2019) Studie Virtual Reality /Augmented Reality 2019. Online unter: https://whitepaper.computerwoche.de/uploads/files/3d3b2d7bae6728d18bbb1a2eea32d71ae6755c18.pdf (Letzter Zugriff: 18.12.2021)
Plattform Industrie 4.0 (2021) Was ist Industrie?. BMWI. Online unter: https://www.plattform-i40.de/IP/Navigation/DE/Industrie40/WasIndustrie40/was-ist-industrie-40.html (Letzter Zugriff: 18.12.2021)
Roth A. (2016) Einführung und Umsetzung von Industrie 4.0. Grundlagen, Vorgehensmodell und Use Cases aus der Praxis, Springer, Berlin, Heidelberg.
Statista (2021) Für welche Inhalte haben Sie Virtual Reality bereits genutzt? Online unter: https://de.statista.com/statistik/daten/studie/1247695/umfrage/umfrage-zu-beliebten-einsatzszenarien-fuer-virtual-reality-in-deutschland/ (Letzter Zugriff: 18.12.2021)
Tönnis M. (2010) Augmented Reality. Informatik im Fokus, Springer, Berlin, Heidelberg. Online unter: https://doi.org/10.1007/978-3-642-14179-9_1 (Letzter Zugriff: 18.12.2021)
VR Dynamix GmbH (2020) Wird Virtual Reality in der Industrie 4.0 zum zentralen Bestandteil? Online unter: https://vr-dynamix.com/virtual-reality-industrie-4-0/ (Letzter Zugriff: 18.12.2021)

Stefanie Barthelme
- Student im Masterstudiengang Wirtschaftsingenieurwesen

ETL, ELT und Streaming ETL – eine wissenschaftliche Übersicht
05.08.2019
Abstract
Die Integration von unternehmerischen Daten aus verschiedensten Quellen wird IT-seitig durch den Extract-Transform-Load-Prozess (ETL) abgebildet. Das Ziel dieses Prozesses ist es, dem Endnutzer alle relevanten Daten einheitlich formatiert in Data Warehouses zur Verfügung zu stellen. In diesem Artikel werden im Zuge einer Literaturrecherche verschiedene Ausprägungen dieses Prozesses vorgestellt und miteinander verglichen. Zudem wird eine aktuelle Übersicht über am Markt verfügbare Tools zur Datenintegration inklusive ihrer Stärken und Schwächen dargestellt. Als wichtiges Ergebnis dieses Artikels ist festzuhalten, dass der Prozess der Datenintegration in der Literatur oft unabhängig von der tatsächlichen Prozessreihenfolge als ETL bezeichnet wird, auch wenn es sich technisch gesehen und den alternativen Extract-Load-Transform-Prozess (ELT) handelt. Eine weitere Erkenntnis ist, dass es mit Streaming ETL ein Verfahren gibt, dass die Datenintegration in Echtzeit ermöglicht.
Keywords: Datenintegration, ETL, ELT, Extract-Load-Transform, Extract-Transform-Load, Datenbankprozesse
Einleitung
Im modernen Geschäftsalltag ist die Verfügbarkeit von verschiedensten Informationen per Mausklick zur Selbstverständlichkeit geworden. Die Bereitstellung von brauchbaren Daten an den Endnutzer erfolgt üblicherweise über Data Warehouses. Diese tragen Daten aus einer oft heterogenen Landschaft von Quellsystemen zusammen und integrieren sie zu für den Anwender verwendbaren Informationen. Dies geschieht traditionell mit Extract-Transform-Load (ETL) Prozessen (Vassiliadis, 2009). Seit der Etablierung dieser Technik haben sich jedoch tiefgreifende wirtschaftliche und technische Änderungen durchgesetzt, die sich unweigerlich auch auf die Gestaltung der Datenintegration auswirken. Zu nennen sind hier unter anderem die stark gefallenen Preise für Speicherplatz, gesunkene Zugriffszeiten, die Etablierung von Cloud- bzw. Online-Speichern und die Entwicklung hin zu Software-as-a-Service (Hoisl, 2019; Liao et al., 2017; Buxmann et al., 2008). Problematisch ist es jedoch, dass aufgrund der sehr rudimentären Einteilung des Datenintegrationsprozesses in drei Schritte eine einheitliche Definition erschwert wird. So wird häufig nicht speziell zwischen Extract-Transform-Load und Extract-Load-Transform unterschieden. Da es sich bei letztgenanntem Prozess jedoch um eine wesentlich aktuellere Methode handelt, ist es oft schwer zu erkennen, um welche Prozessart es sich in einer Quelle handelt.
Ziel dieser Recherche ist es, verschiedene Gestaltungsmöglichkeiten des ETL-Prozesses zu identifizieren und gegenüberzustellen. Zudem soll eine kurze Übersicht über die gängigsten Datenintegrations-Tools gegeben werden, die auf der Analyse literarischer Quellen und Herstellerangaben beruht.
Extract-Transform-Load
Extract-Transform-Load Prozesse bilden die Grundlage zur Bereitstellung von Daten aus einer inhomogenen Quellenbasis in Data Warehouses (siehe Abbildung 1). Der erste Prozessschritt Extract entspricht der Extraktion von Daten aus verschiedenen Quellen. Dies können beispielsweise Webseiten, verschiedene Arten von Dokumenten und Dateien, Business-Anwendungen etc. sein (Stephanidis et al., 2009).
Die anschließende Transformation der Daten findet innerhalb eines Arbeitsbereiches, der Staging Database, statt. Hier werden die Rohdaten in eine vorverarbeitete Form gebracht. Dies betrifft unter anderem die Beseitigung von Duplikaten, Umrechnung von Einheiten, Normalisierung, Gruppierung und Überprüfung der Plausibilität der Daten (Bansal und Kagemann, 2015).
Beim Load-Prozess werden die aufbereiteten Daten in die Zieldatenbank übertragen und stehen somit dem Endnutzer zur Verfügung (Vaisman und Zimányi, 2014).
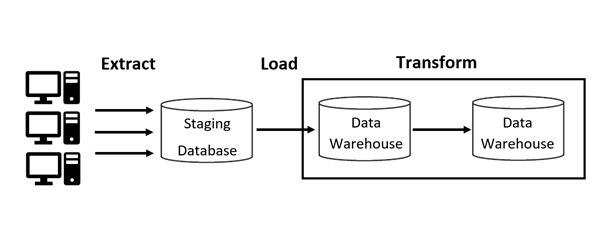
Abbildung 1: Schematische Darstellung des ETL-Prozesses nach Davenport (2009)
ETL-Prozesse haben den Vorteil, dass sie auf die benötigten Daten zugeschnitten sind. Nur diese werden aus den Quellen extrahiert. Somit werden auch bei der Transformation Kapazitäten gespart und es werden keine falschen, redundanten oder nicht benötigten Daten in die Zieldatenbank übertragen. Lediglich relevante Daten sind somit in der Zieldatenbank vorhanden.
Allerdings sind ETL-Prozesse dadurch unflexibel und aufgrund der starken Abhängigkeiten bei Extraktion und Transformation nur schwer erweiterbar (Gour et al., 2010). Der komplette ETL-Prozess benötigt viel Rechenleistung in einer separaten Staging Database und findet deshalb in der Praxis überwiegend zur Tageszeit mit der geringsten Auslastung statt – nachts (Vassiliadis und Simitsis, 2009). Während im moderneren ELT-Verfahren die Rechenleistung der Datenbank zur Transformation genutzt wird, wird beim traditionellen ETL eine zusätzliche Staging Database mit entsprechender Rechenleistung benötigt. Zudem findet die Bearbeitung der einzelnen Jobs in großen Batches überwiegend nachts statt. Dies hat auch den Nachteil zur Folge, dass die im Data Warehouse abgelegten Daten bis zu 24 Stunden alt sein können.
Außerdem müssen beim ETL-Verfahren Daten aus dem operativen Geschäftsbetrieb häufig extrahiert werden um mit möglichst geringer Verzögerung im Data Warehouse zur Verfügung zu stehen. Dies führt generell dazu, dass die Anzahl der durchgeführten Extraktionsprozesse deutlich steigt, jedoch die Menge der Daten pro Extraktionsprozess sinkt. Die Transformation kann aufgrund ihrer Zeitintensivität nicht mehr bei jedem Warehouse-Aktualisierungsprozess durchgeführt werden. Dies führt zu einem neuen Ansatz, der die Verfügbarkeit aktueller Daten realisierbar macht (Wibowo, 2015).
| Funktionsweise | Vorteile | Nachteile |
| Extraktion der Daten aus verschiedenen Quellen -> Transformation der Daten in der Staging Area -> Laden der Daten in die Zieldatenbank | Nur relevante Daten werden geladen, dadurch Einsparung von Speicherplatz in der Zieldatenbank |
|
Extract-Load-Transform
Zur Handhabung der bereits genannten Nachteile des traditionellen ETL-Prozesses entwickelte sich ein neues Vorgehen: Extract-Load-Transform (ELT). Die Transformation findet hier erst nach dem Laden der Daten in das Data Warehouse statt. Diese Abwandlung des ursprünglichen ETL-Prozesses löst viele Probleme und schafft die Möglichkeit, zur Transformation der Daten die Rechenleistung der Zieldatenbank zu nutzen (Wibowo, 2015; Sabtu et al., 2017).
Abbildung 2: Schematische Darstellung des ELT-Prozesses nach Davenport (2009)
Beim ELT-Prozess werden alle Rohdaten aus den Datenquellen extrahiert. Somit sind gegebenenfalls auch redundante oder nutzlose Daten vorhanden, die in das Data Warehouse geladen werden und dort erst bei der Transformation beseitigt oder aussagekräftig gemacht werden (Ranjan, 2009). Dieses Vorgehen wurde erst durch gesunkene Preise für Speicherplatz ermöglicht (Hoisl, 2019). Denn zu Beginn der ETL-Technologie war es schlichtweg zu teuer, große Datenmengen zu speichern. Um den benötigten Speicherplatz gering zu halten musste die Transformation vor dem Laden in die Zieldatenbank stattfinden. Als sich dieses Problem durch geringere Kosten löste, wurde das Speichern aller Daten in der Zieldatenbank mit anschließender Transformation ermöglicht.
Den Anwendern stand jedoch nur ein geringes Angebot an ELT-Tools zur Verfügung, als ELT begann, sich als Alternative zum traditionellen ETL-Prozess zu etablieren (Ranjan, 2009; Davenport, 2009). Heutzutage hat jedoch nahezu jeder ETL-Anbieter auch ELT-Lösungen im Portfolio (Vassiliadis und Simitsis, 2009, S. 7).
Ein großer Vorteil der ELT-Technologie ist die bessere Hardwarenutzung im Vergleich zu ETL. Dadurch, dass die Transformation in der Zieldatenbank stattfindet, wird die Rechenleistung des Data Warehouse genutzt (Ranjan, 2009; Vassiliadis und Simitsis, 2009, S. 7; Davenport, 2009). Somit ist der ELT-Prozess durch Hardwareerweiterungen des Data Warehouse beliebig skalierbar und hängt nicht von der Rechenleistung der Staging Area ab (Vassiliadis und Simitsis, 2009).
Es bleibt jedoch festzuhalten, dass die Prozesse der Datenintegration häufig nicht einheitlich als ETL oder ELT betitelt werden. Überwiegend kommt der Begriff ETL zum Einsatz. Die konkrete Betitelung als ELT wird oft nur verwendet, wenn besonders hervorgehoben werden soll, dass der Transform-Prozess als letztes stattfindet. Außerdem existieren auch Mischformen aus beiden Möglichkeiten, beispielsweise ETLT (Vassiliadis, 2009). Hier finden einfache Schritte der Transformation vor dem Laden statt, während die rechenintensiven Transformationsvorgänge in der Zieldatenbank durchgeführt werden. Dies erschwert die Recherche deutlich, da für eine genaue Zuordnung zu ETL oder ELT die in einer Quelle genannte Prozessabfolge detailliert betrachtet werden muss. Allein anhand der Abkürzungen ETL oder ELT lässt sich deshalb keine genaue Einordnung vornehmen.
| Funktionsweise | Vorteile | Nachteile |
| Extraktion der Daten aus verschiedenen Quellen -> Laden aller Daten in die Zieldatenbank -> Transformation der Daten innerhalb der Zieldatenbank |
|
|
Streaming ETL
Der Data-Warehouse-Aktualisierungsprozess bei ETL findet üblicherweise in einem Zeitfenster mit geringer Auslastung statt, um den operativen Betrieb nicht zu stören und die relevante Rechenleistung zur Verfügung zu haben. Dies ist überwiegend nachts der Fall (Vassiliadis, 2009). Der ETL-Prozess wird überwiegend mit Batch-Verarbeitung durchgeführt. Das heißt, dass alle angefallenen Datensätze und Jobs automatisch sequentiell abgearbeitet werden (Lackes und Siepermann, 2018). Die Folge ist aber, dass die in der Zieldatenbank existenten Datensätze bis zu 24 Stunden alt sind. Die Aktualität der Daten ist somit für die Auswertung zeitlich kritischer Daten ungenügend. Diese Problematik kann durch die Unterteilung der großen Batches in kleinere Mini-Jobs, die beispielsweise stündlich durchgeführt werden, minimiert werden (Mukherjee und Kar, 2017). Dadurch können jedoch im operativen Betrieb kurze Ausfallzeiten entstehen. Eine weitere Methode, die die Aktualität der Daten in der Zieldatenbank deutlich verbessern kann, ist Change Data Capture (CDC) (Berkani und Bellatreche, 2018). Hier werden bei jedem Aktualisierungsprozess lediglich neue oder geänderte Daten extrahiert, transformiert und geladen (siehe Abbildung 3). Dadurch wird die Datenmenge deutlich reduziert und die Geschwindigkeit des Datenflusses deutlich erhöht. Die Latenzen können somit auf Minuten oder Sekunden reduziert werden (Biswas et al., 2019).

Abbildung 3: Schematische Darstellung des Streaming ELT-Prozesses nach Li und Mao (2015)
Dennoch kann hierbei nicht von Echtzeit gesprochen werden, da der Extraktionsprozess im Pull-Prinzip als Batch-Verarbeitung durchgeführt wird. Echtzeitbetrieb ist als Betriebsart definiert, bei der jeder Job unmittelbar nach dessen Auftreten abgearbeitet wird (Siepermann, 2018). Dies ist nur der Fall, wenn neue oder geänderte Daten den ETL-Prozess im Push-Verfahren durchlaufen. Dieser Vorgang wird als CDC-Trigger bezeichnet. Hier wird die Prozesskette nicht im Pull-Prinzip in einem gewissen Zeitintervall durchgeführt, sondern im Push-Verfahren immer dann, wenn neue oder geänderte Datensätze in den Quellen existieren. Der ETL-Prozess wird somit jeweils nur von sehr kleinen Datenpaketen durchlaufen, was eine sehr schnelle Abarbeitung ermöglicht (Berkani und Bellatreche, 2018; Mohammed Muddasir und Raghuveer, 2017; Biswas et al., 2019). Da der Prozess von den Datenquellen selbst getriggert wird, entspricht diese Vorgehensweise der Definition von Siepermann (2018) zufolge einem Echtzeitverfahren. In der Literatur wird diese Ausprägung des Datenintegrationsprozesses als Real-Time ETL oder Streaming ETL bezeichnet.
Hier ist es wichtig zu erwähnen, dass der Fokus dieser Bezeichnung auf Real-Time bzw. Streaming liegt. ETL wird in diesem Kontext erneut stellvertretend für den generellen Datenintegrationsprozess verwendet, unabhängig von der genauen Reihenfolge der Prozesse Extract, Transform und Load. Deshalb wird beispielsweise auch von ETL gesprochen, wenn die Transformation teilweise oder vollständig nach dem Laden in die Zieldatenbank stattfindet (Berkani und Bellatreche, 2018).
| Funktionsweise | Vorteile | Nachteile |
| Auftreten von neuen oder geänderten Datensätze triggert den Prozess -> Laden des Datensatzes in die Zieldatenbank -> Transformation des Datensatzes | · Daten sind in Echtzeit in der Zieldatenbank verfügbar
· Wegfall von großen Batch-Jobs |
· Unübersichtlicher Markt, da relativ neue Technik (siehe Tabelle 4) |
Tools zur Datenintegration
Im Folgenden soll ein Überblick über die aktuell gängigsten ETL- und ELT-Tools gegeben werden. Im aktuellsten Vergleich von ETL Tools werden die acht umsatzstärksten Produkte samt ihrer Stärken und Schwächen vorgestellt (Harvey, 2018). Diese Angaben werden im Folgenden mit Informationen aus den Artikeln von Mukherjee und Kar (2017) und Greengard (2018) ergänzt und systematisch in Tabellenform dargestellt. Dabei werden auch Informationen aus Datenblättern und Homepages der Produktanbieter verwendet.
In Tabelle 4 sind die Ergebnisse des Vergleichs übersichtlich dargestellt. Zu jedem Produkt wurden jeweils Stärken und Schwächen herausgearbeitet. Zudem wurde eine Zuordnung jedes Tools zum Prozess ETL oder ELT anhand der von den Quellen beschriebenen Prozessabfolge vorgenommen. Teilweise können die Tools auch beide Prozesse abbilden und sind deshalb entsprechend in der Tabelle doppelt zugeordnet. Das Tool „SAP Data Services“ konnte keinem der beiden Prozesse zugeordnet werden, da sich keine Informationen zum genauen Prozessablauf finden lassen (siehe Tabelle 4).
Als Fazit aus der in Tabelle 4 dargestellten Marktübersicht der gängigsten ETL- und ELT-Tools lässt sich festhalten, dass viele Anbieter den Prozess der Datenintegration unabhängig von der tatsächlichen Prozessreihenfolge als ETL bezeichnen. In vielen Fällen handelt es sich jedoch um ein ELT-Verfahren oder um eine hybride Mischform aus ETL und ELT. Hier bestätigt sich erneut die Erkenntnis, dass die Betitelung eines Datenintegrationsverfahrens als ETL oder ELT nicht zwangsweise mit der genauen Prozessreihenfolge zusammenhängt. Zudem lässt sich feststellen, dass alle Anbieter ihre Lösung im Paket mit Software und der benötigten Infrastruktur als Software-as-a-Service bereitstellen. Hier ermöglicht die Etablierung von Cloud-Speichern die Handhabung der ETL Prozesse über Weboberflächen. Dadurch entfällt für den Kunden die Anschaffung zusätzlicher Hardware. Zudem sind häufig vereinfachte Benutzeroberflächen vorzufinden, die die Gestaltung der Datenintegration ohne detallierte Programmierkenntnisse beispielsweise per Drag and Drop mit Hilfe vordefinierter Bausteine ermöglicht. Dadurch ist der komplette Prozess wesentlich flexibler und nicht, wie zu Beginn der ETL-Technik, starr definiert und nur schwer anzupassen.
| Anbieter | Produkt | Stärken | Schwächen | ETL | ELT | Sonstiges |
| Informatica | Data Integration Platform | Breites Produktspektrum (Harvey, 2018; Informatica GmbH, 2019) einfache Handhabung (Greengard, 2018) | Obere Preisklasse (Harvey, 2018) Funktionalitäten der einzelnen Produkte grenzen sich schlecht voneinander ab (Harvey, 2018) | x (Informatica GmbH, 2019) | x (Informatica GmbH, 2019) | CDC wird genutzt, dadurch Streaming-ETL möglich (Mukherjee und Kar, 2017) |
| Dell Boomi | Dell Boomi Platform | Benutzerfreundliche GUI (Greengard, 2018) vordefinierte Konnektoren (Boomi, 2018) | Standardoberfläche unterstützt nicht alle Funktionen, Erweiterung nur über Skripte möglich (Greengard, 2018) | x (Boomi, 2018) | Große Kundenbasis (Harvey, 2018) | |
| IBM | InfoSphere DataStage | Unterstützt auch stark heterogene Datenbasen (Greengard, 2018) Starke Skalierbarkeit durch das parallele Abarbeiten von Jobs (Mukherjee und Kar, 2017) | Verwirrende Preisgestaltung (Harvey, 2018) Edge-Funktionalitäten schwächer als im Vergleich zur Konkurrenz (Greengard, 2018) | x (IBM Corporation, 2016) | Streaming ETL durch CDC Capture möglich (Mukherjee und Kar, 2017) | |
| SAS | Data Management | Benutzerfreundliche GUI (Harvey, 2018) | Obere Preisklasse (Harvey, 2018) | x (SAS Institute Inc, 2017) | x (SAS Institute Inc, 2017) | Große Kundenbasis (Harvey, 2018) |
| SAP | Data Services | Besonders geeignet für den ETL-Prozess zwischen SAP ERP und SAP Hana (Harvey, 2018; SAP America, 2018) | Obere Preisklasse (Harvey, 2018) Schnittstellenprobleme mit anderen Anwendungen (Greengard, 2018) | Kostenabrechnung über die Anzahl der genutzten CPU Kerne (SAP America, 2018) | ||
| Oracle | Data Integration Platform Cloud | Untere Preisklasse (Mukherjee und Kar, 2017) Architektur ist für große Datenmengen geeignet (Greengard, 2018; ORACLE Deutschland B.V. & Co. KG, 2018) | Schlechte Dokumentation für das Fehlerhandling (Harvey, 2018; Greengard, 2018) | x (Mukherjee und Kar, 2017) | Verbesserung der Datenqualität durch Herausfiltern von schlechten Datensätzen vor dem Laden in die Zieldatenbank (Mukherjee und Kar, 2017) | |
| Talend | Data Management Platform | Untere Preisklasse (Harvey, 2018) unterstützt große Anzahl an Quellformaten | Teilweise Performanceprobleme (Greengard, 2018) | x (Talend Germany GmbH, 2019) | x (Talend Germany GmbH, 2019) | kostenlose Testversion verfügbar (Talend Germany GmbH, 2019) |
| Microsoft | Azure Data Factory | Untere Preisklasse (Harvey, 2018) vordefinierte Bausteine oder eigene Skripte möglich (Microsoft Corporation, 2019) einfache Integration mit Microsoft SQL Server Integration Services (SSIS) | Relativ unbekannt, da neu am Markt (Harvey, 2018) | x (Microsoft Corporation, 2019) | x (Microsoft Corporation, 2019) | Nutzungsbasierte Kostenabrechnung (hp) |
Im Rahmen dieser Recherche wurde ebenfalls eine Anfrage an die Hersteller der acht Tools in Tabelle 4 durchgeführt. In dieser Anfrage wurden die Hersteller im ersten Schritt gefragt, ob Sie ihr Produkt eher als ETL, ELT oder Hybridform einschätzen. In der zweiten Frage sollten die Hersteller begründen, in welchem der drei Prozesschritte Extract, Transform oder Load sie die Kernkompetenz ihres Produktes sehen. Eine Abgrenzung des Produktes zur Konkurrenz mit Begründung war Gegenstand der letzten Frage. Insgesamt beantworteten nur drei der Softwareantbieter die Fragen (siehe Anhang). Die Antworten sind jedoch nur eingeschränkt aussagekräftig, da beispielse alle drei Hersteller als Kernkompetenz Ihres Tools alle drei Prozessschritte Extract, Transform und Load angeben, obwohl nach einem einzigen Prozessschritt mit Begründung gefragt wurde. Auch gaben die drei Hersteller bei Frage eins mehrere Antworten, obwohl eine der drei Antwortmöglichkeiten ausgewählt und begründet werden sollte. Da nicht von allen Herstellern eine Antwort vorliegt und die drei beantworteten Fragebögen nicht aussagekräftig sind, lassen sich aus der Umfrage keine weitere Schlüsse ziehen. Die Informationen aus der Umfrage werden deshalb nicht in der Gegenüberstellung der acht Tools zur Datenintegration (siehe Tabelle 4) verwendet.
Zusammenfassung
In diesem Artikel wurden verschiedene Arten der Datenintegration wissenschaftlich aufgearbeitet und gegenübergestellt. Die beiden grundliegenden Verfahren ETL und ELT wurden samt ihren Vor- und Nachteilen vorgestellt. Zudem wurden die Techniken CDC und CDC-Trigger dargestellt, die den kompletten Prozess der Datenintegration in nahezu Echtzeit ermöglichen. Das letzte Element dieser Recherche war eine kurze Übersicht der gängigsten am Markt angebotenen ETL- und ELT-Tools.
Als Erkenntnis dieses Artikels lässt sich festhalten, dass die Data Warehouse Refreshment-Prozesse heutzutage nicht mehr ausschließlich nachts als große Batch-Jobs stattfinden. Die Vorgehensweise hat sich stark auf kleine Datenpakete fokussiert, die während dem laufenden Geschäftsbetrieb die Datenintegrationsprozesse durchlaufen. Dadurch ist es in der Praxis möglich, dem Endnutzer operative Daten aus verschiedensten Datenquellen in Echtzeit in Data Warehouses zu sammeln. Als weiterer Erkenntnisgewinn ist die oft fehlerhafte Bezeichnung den Datenintegrationsprozesses als ETL zu nennen. In der Praxis hat sich der Begriff ETL so stark etabliert, dass er häufig stellvertretend für den generellen Datenintegrationsprozess verwendet wird. Dabei wird die genaue Abfolge der einzelnen Prozessschritte jedoch außer Acht gelassen. Deshalb können allein anhand der Betitelung als ETL oder ELT keine Rückschlüsse auf die technische Abfolge der Datenintegration gemacht werden. Deshalb muss bei einer Recherche in diesem Themenbereich immer die genaue Prozessabfolge untersucht werden, um eine Technologie aus technischer Sicht korrekt als ETL oder ELT bezeichnen zu können.
Die Gegenüberstellung der ETL-Tools baut lediglich auf literarischen Quellen und Herstellerangaben auf. Um eine detallierte Betrachtung der ETL-Tools auf der Basis von Erfahrungswerten durchzuführen, muss jedes Tool individuell getestet werden. Nur so können die Stärken und Schwächen in der Praxis evaluiert werden.
Literaturverzeichnis
Bansal, S.K. und Kagemann, S. (2015), „Integrating Big Data: A Semantic Extract-Transform-Load Framework”, Computer, Jg. 48 Nr. 3, S. 42–50.
Berkani, N. und Bellatreche, L. (2018), „Streaming ETL in Polystore Era”, in Vaidya, J. und Li, J. (Hrsg.), Algorithms and architectures for parallel processing: 18th International Conference, ICA3PP 2018, Guangzhou, China, November 15-17, 2018, proceedings, LNCS sublibrary: SL1 – Theoretical computer science and general issues, Bd. 11336, Springer, Cham, Switzerland, S. 560–574.
Biswas, N., Sarkar, A. und Mondal, K.C. (2019), „Efficient incremental loading in ETL processing for real-time data integration”, Innovations in Systems and Software Engineering, Jg. 5 Nr. 3, S. 1.
Boomi, I. (2018), „Dell Boomi Datasheet”, [online] verfügbar unter: https://boomi.com/wp-content/uploads/Dell-Boomi-Integration-Datasheet.pdf (zugegriffen am 02.07.2019).
Buxmann, P., Hess, T. und Lehmann, S. (2008), „Software as a Service”, WIRTSCHAFTSINFORMATIK, Jg. 50 Nr. 6, S. 500–503.
Davenport, R. (2009), „ETL vs ELT. A Subjective View”, [online] verfügbar unter: https://pdfs.semanticscholar.org/1d9e/7bf640c94f4014247d6a1dc46a5af5e79d5e.pdf.
Gour, V., Sarangdevot, S.S., Tanwar, G.S. und Sharma, A. (2010), „Improve Performance of Extract, Transform and Load (ETL) in Data Warehouse”, International Journal on Computer Science and Engineering, Jg. 2 Nr. 3, S. 786–789.
Greengard, S. (2018), „Top 10 Data Integration Tools”, [online] verfügbar unter: https://www.datamation.com/big-data/top-data-integration-tools.html (zugegriffen am 15.07.2019).
Harvey, C. (2018), „Top 8 ETL Tools”, [online] verfügbar unter: https://www.datamation.com/big-data/top-8-etl-tools.html (zugegriffen am 15.07.2019).
Hoisl, B. (2019), „Grundlagen des Digital Mindset”, in Hoisl, B. (Hrsg.), Produkte digital-first denken: Wie Unternehmen software-basierte Produktinnovation erfolgreich gestalten, Springer Gabler, Wiesbaden, S. 93–123.
IBM Corporation (2016), „Flexible integration Flexible Integration with IBM InfoSphere DataStage V11.5”, [online] verfügbar unter: https://www.ibm.com/downloads/cas/5QV1WDAY (zugegriffen am 08.07.2019).
Informatica GmbH (2019), „Homepage”, [online] verfügbar unter: https://www.informatica.com/de/products/data-integration.html (zugegriffen am 02.07.2019).
Lackes, R. und Siepermann, M. (2018), „Stapelbetrieb – Ausführliche Definition”, [online] verfügbar unter: https://wirtschaftslexikon.gabler.de/definition/stapelbetrieb-43352/version-266683 (zugegriffen am 03.06.2019).
Li, X. und Mao, Y. (2015), „Real-Time data ETL framework for big real-time data analysis”, in 2015 IEEE International Conference on Information and Automation: In conjunction with 2015 IEEE International Conference on Automation and Logistics conference program digest August 8-10, 2015, the old town of Lijiang, Yunnan, China, Lijiang, China, 8/8/2015 – 8/10/2015, IEEE, Piscataway, NJ, S. 1289–1294.
Liao, W.-H., Chen, P.-W. und Kuai, S.-C. (2017), „A Resource Provision Strategy for Software-as-a-Service in Cloud Computing”, Procedia Computer Science, Jg. 110, S. 94–101.
Microsoft Corporation (2019), „Data Factory”, [online] verfügbar unter: https://azure.microsoft.com/de-de/services/data-factory/ (zugegriffen am 15.07.2019).
Mohammed Muddasir, N. und Raghuveer, K. (2017), „CDC and Union based near real time ETL”, in Technologies, I.C.o.E.C.a.I. (Hrsg.), 2017 2nd International Conference on Emerging Computation and Information Technologies (ICECIT): 15-16 Dec. 2017, Tumakuru, 12/15/2017 – 12/16/2017, IEEE, [Piscataway, NJ], S. 1–5.
Mukherjee, R. und Kar, P. (2017), „A Comparative Review of Data Warehousing ETL Tools with New Trends and Industry Insight”, in Padma Sai, Y., Garg, D. und Conference, I.I.A.C. (Hrsg.), 7th IEEE International Advanced Computing Conference: IACC 2017 5-7 January 2017, VNR Vignana Jyothi Institute of Engineering and Technology, Hyderabad, Telangana, India proceedings, Hyderabad, India, 1/5/2017 – 1/7/2017, IEEE, Piscataway, NJ, S. 943–948.
ORACLE Deutschland B.V. & Co. KG (2018), „Experience Powerful Data Integration in the Cloud”, [online] verfügbar unter: https://cloud.oracle.com/opc/paas/ebooks/Oracle_Data_Integration_Platform_Cloud.pdf (zugegriffen am 02.07.2019).
Ranjan, V. (2009), „A Comparative Study between ETL (Extract-Transform-Load) and E-LT (ExtractLoad-Transform) approach for loading data into a Data Warehouse”, [online] verfügbar unter: https://pdfs.semanticscholar.org/b6aa/6cd1aec2c36c8d7e573b109a8d1d2e87b593.pdf.
Sabtu, A., Azmi, N.F.M., Sjarif, N.N.A., Ismail, S.A., Yusop, O.M., Sarkan, H. und Chuprat, S. (2017), „The challenges of Extract, Transform and Loading (ETL) system implementation for near real-time environment”, in Systems, I.C.o.R.a.I.I. in (Hrsg.), Social transformation through data science: ICRIIS 2017 5th International Conference on Research and Innovation in Information Systems Adya Hotel, Langkawi, Kedah, 16-17th July 2017, Langkawi, Malaysia, 7/16/2017 – 7/17/2017, IEEE, Piscataway, NJ, S. 1–5.
SAP America, I. (2018), „Enterprise Data Management Software”, [online] verfügbar unter: https://www.sap.com/products/data-services.html#product-overview (zugegriffen am 02.07.2019).
SAS Institute Inc (2017), „SAS Data Management Fact Sheet”, [online] verfügbar unter: https://www.sas.com/content/dam/SAS/en_us/doc/factsheet/sas-data-management-102451.pdf (zugegriffen am 08.07.2019).
Siepermann, M. (2018), „Echtzeitbetrieb – Ausführliche Definition”, [online] verfügbar unter: https://wirtschaftslexikon.gabler.de/definition/echtzeitbetrieb-34713/version-258211 (zugegriffen am 17.06.2019).
Stephanidis, C., Mellin, J., Berndtsson, M., Berndtsson, J.M.M., Veijalainen, J., Jensen, E.C., Beitzel, S.M., Frieder, O., Schweikardt, N., Amsler, R.A., Shabo, A., Aref, W.G., Allen, R.B., Zhang, E., Zhang, Y., Cudré-Mauroux, P., Dong, G., Li, J., Zhou, Z.-H., Wong, J., Tompa, F.W., Flurry, G., Gerstley, L., Song, I.-Y., Chen, P.P., Fagin, R., O’Neil, P., Carroll, M., Pehcevski, J., Piwowarski, B., Zhou, J., Hong, M., Demers, A., Gehrke, J., Riedewald, M., Sharon, G., Etzion, O., Chandy, K.M., Ericsson, A., Jensen, C.S., Snodgrass, R.T., Wasserkrug, S., Niblett, P., Ammon, R. von, Shapiro, M., Kemme, B., Weiner, M., Peleg, M., Hardavellas, N., Pandis, I., Hinterberger, H., Libkin, L., Thalheim, B., Chrysanthis, P.K., Ramamritham, K., Zhang, D., Manolopoulos, Y., Theodoridis, Y., Tsotras, V.J., Vassiliadis, P. und Simitsis, A. (2009), „Extraction, Transformation, and Loading”, in ÖZSU, M.T. und LIU, L. (Hrsg.), Encyclopedia of database systems, Springer, New York, London, S. 1095–1101.
Talend Germany GmbH (2019), „Data Integration Technische Details”, [online] verfügbar unter: https://de.talend.com/products/specifications-data-integration/ (zugegriffen am 09.07.2019).
Vaisman, A. und Zimányi, E. (2014), „New Data Warehouse Technologies”, in Vaisman, A. und Zimányi, E. (Hrsg.), Data Warehouse Systems, Springer Berlin Heidelberg, Berlin, Heidelberg, S. 507–537.
Vassiliadis, P. (2009), „A Survey of Extract–Transform–Load Technology”, International Journal of Data Warehousing and Mining, Jg. 5 Nr. 3, S. 1–27.
Vassiliadis, P. und Simitsis, A. (2009), „Near Real Time ETL”, in Kozielski, S. und Wrembel, R. (Hrsg.), New trends in data warehousing and data analysis, Annals of Information Systems, Bd. 3, Springer, [New York], S. 1–31.
Wibowo, A. (2015), „Problems and available solutions on the stage of Extract, Transform, and Loading in near real-time data warehousing (a literature study)”, in 2015 International Seminar on Intelligent Technology and Its Applications (ISITIA): Proceeding Surabaya, Indonesia, 20-21 May 2015, Surabaya, Indonesia, 5/20/2015 – 5/21/2015, IEEE, [Piscataway, New Jersey], S. 345–350.

Andreas Ott
- Studentischer Mitarbeiter im Forschungsprojekt OBerA an der FHWS
- Student im Masterstudiengang Wirtschaftsingenieurwesen
ETL, ELT und Streaming ETL – eine wissenschaftliche Übersicht
05.08.2019
Abstract
Die Integration von unternehmerischen Daten aus verschiedensten Quellen wird IT-seitig durch den Extract-Transform-Load-Prozess (ETL) abgebildet. Das Ziel dieses Prozesses ist es, dem Endnutzer alle relevanten Daten einheitlich formatiert in Data Warehouses zur Verfügung zu stellen. In diesem Artikel werden im Zuge einer Literaturrecherche verschiedene Ausprägungen dieses Prozesses vorgestellt und miteinander verglichen. Zudem wird eine aktuelle Übersicht über am Markt verfügbare Tools zur Datenintegration inklusive ihrer Stärken und Schwächen dargestellt. Als wichtiges Ergebnis dieses Artikels ist festzuhalten, dass der Prozess der Datenintegration in der Literatur oft unabhängig von der tatsächlichen Prozessreihenfolge als ETL bezeichnet wird, auch wenn es sich technisch gesehen und den alternativen Extract-Load-Transform-Prozess (ELT) handelt. Eine weitere Erkenntnis ist, dass es mit Streaming ETL ein Verfahren gibt, dass die Datenintegration in Echtzeit ermöglicht.
Keywords: Datenintegration, ETL, ELT, Extract-Load-Transform, Extract-Transform-Load, Datenbankprozesse
Einleitung
Im modernen Geschäftsalltag ist die Verfügbarkeit von verschiedensten Informationen per Mausklick zur Selbstverständlichkeit geworden. Die Bereitstellung von brauchbaren Daten an den Endnutzer erfolgt üblicherweise über Data Warehouses. Diese tragen Daten aus einer oft heterogenen Landschaft von Quellsystemen zusammen und integrieren sie zu für den Anwender verwendbaren Informationen. Dies geschieht traditionell mit Extract-Transform-Load (ETL) Prozessen (Vassiliadis, 2009). Seit der Etablierung dieser Technik haben sich jedoch tiefgreifende wirtschaftliche und technische Änderungen durchgesetzt, die sich unweigerlich auch auf die Gestaltung der Datenintegration auswirken. Zu nennen sind hier unter anderem die stark gefallenen Preise für Speicherplatz, gesunkene Zugriffszeiten, die Etablierung von Cloud- bzw. Online-Speichern und die Entwicklung hin zu Software-as-a-Service (Hoisl, 2019; Liao et al., 2017; Buxmann et al., 2008). Problematisch ist es jedoch, dass aufgrund der sehr rudimentären Einteilung des Datenintegrationsprozesses in drei Schritte eine einheitliche Definition erschwert wird. So wird häufig nicht speziell zwischen Extract-Transform-Load und Extract-Load-Transform unterschieden. Da es sich bei letztgenanntem Prozess jedoch um eine wesentlich aktuellere Methode handelt, ist es oft schwer zu erkennen, um welche Prozessart es sich in einer Quelle handelt.
Ziel dieser Recherche ist es, verschiedene Gestaltungsmöglichkeiten des ETL-Prozesses zu identifizieren und gegenüberzustellen. Zudem soll eine kurze Übersicht über die gängigsten Datenintegrations-Tools gegeben werden, die auf der Analyse literarischer Quellen und Herstellerangaben beruht.
Extract-Transform-Load
Extract-Transform-Load Prozesse bilden die Grundlage zur Bereitstellung von Daten aus einer inhomogenen Quellenbasis in Data Warehouses (siehe Abbildung 1). Der erste Prozessschritt Extract entspricht der Extraktion von Daten aus verschiedenen Quellen. Dies können beispielsweise Webseiten, verschiedene Arten von Dokumenten und Dateien, Business-Anwendungen etc. sein (Stephanidis et al., 2009).
Die anschließende Transformation der Daten findet innerhalb eines Arbeitsbereiches, der Staging Database, statt. Hier werden die Rohdaten in eine vorverarbeitete Form gebracht. Dies betrifft unter anderem die Beseitigung von Duplikaten, Umrechnung von Einheiten, Normalisierung, Gruppierung und Überprüfung der Plausibilität der Daten (Bansal und Kagemann, 2015).
Beim Load-Prozess werden die aufbereiteten Daten in die Zieldatenbank übertragen und stehen somit dem Endnutzer zur Verfügung (Vaisman und Zimányi, 2014).
Abbildung 1: Schematische Darstellung des ETL-Prozesses nach Davenport (2009)
ETL-Prozesse haben den Vorteil, dass sie auf die benötigten Daten zugeschnitten sind. Nur diese werden aus den Quellen extrahiert. Somit werden auch bei der Transformation Kapazitäten gespart und es werden keine falschen, redundanten oder nicht benötigten Daten in die Zieldatenbank übertragen. Lediglich relevante Daten sind somit in der Zieldatenbank vorhanden.
Allerdings sind ETL-Prozesse dadurch unflexibel und aufgrund der starken Abhängigkeiten bei Extraktion und Transformation nur schwer erweiterbar (Gour et al., 2010). Der komplette ETL-Prozess benötigt viel Rechenleistung in einer separaten Staging Database und findet deshalb in der Praxis überwiegend zur Tageszeit mit der geringsten Auslastung statt – nachts (Vassiliadis und Simitsis, 2009). Während im moderneren ELT-Verfahren die Rechenleistung der Datenbank zur Transformation genutzt wird, wird beim traditionellen ETL eine zusätzliche Staging Database mit entsprechender Rechenleistung benötigt. Zudem findet die Bearbeitung der einzelnen Jobs in großen Batches überwiegend nachts statt. Dies hat auch den Nachteil zur Folge, dass die im Data Warehouse abgelegten Daten bis zu 24 Stunden alt sein können.
Außerdem müssen beim ETL-Verfahren Daten aus dem operativen Geschäftsbetrieb häufig extrahiert werden um mit möglichst geringer Verzögerung im Data Warehouse zur Verfügung zu stehen. Dies führt generell dazu, dass die Anzahl der durchgeführten Extraktionsprozesse deutlich steigt, jedoch die Menge der Daten pro Extraktionsprozess sinkt. Die Transformation kann aufgrund ihrer Zeitintensivität nicht mehr bei jedem Warehouse-Aktualisierungsprozess durchgeführt werden. Dies führt zu einem neuen Ansatz, der die Verfügbarkeit aktueller Daten realisierbar macht (Wibowo, 2015).
| Funktionsweise | Vorteile | Nachteile |
| Extraktion der Daten aus verschiedenen Quellen -> Transformation der Daten in der Staging Area -> Laden der Daten in die Zieldatenbank | Nur relevante Daten werden geladen, dadurch Einsparung von Speicherplatz in der Zieldatenbank |
|
Extract-Load-Transform
Zur Handhabung der bereits genannten Nachteile des traditionellen ETL-Prozesses entwickelte sich ein neues Vorgehen: Extract-Load-Transform (ELT). Die Transformation findet hier erst nach dem Laden der Daten in das Data Warehouse statt. Diese Abwandlung des ursprünglichen ETL-Prozesses löst viele Probleme und schafft die Möglichkeit, zur Transformation der Daten die Rechenleistung der Zieldatenbank zu nutzen (Wibowo, 2015; Sabtu et al., 2017).
Abbildung 2: Schematische Darstellung des ELT-Prozesses nach Davenport (2009)
Beim ELT-Prozess werden alle Rohdaten aus den Datenquellen extrahiert. Somit sind gegebenenfalls auch redundante oder nutzlose Daten vorhanden, die in das Data Warehouse geladen werden und dort erst bei der Transformation beseitigt oder aussagekräftig gemacht werden (Ranjan, 2009). Dieses Vorgehen wurde erst durch gesunkene Preise für Speicherplatz ermöglicht (Hoisl, 2019). Denn zu Beginn der ETL-Technologie war es schlichtweg zu teuer, große Datenmengen zu speichern. Um den benötigten Speicherplatz gering zu halten musste die Transformation vor dem Laden in die Zieldatenbank stattfinden. Als sich dieses Problem durch geringere Kosten löste, wurde das Speichern aller Daten in der Zieldatenbank mit anschließender Transformation ermöglicht.
Den Anwendern stand jedoch nur ein geringes Angebot an ELT-Tools zur Verfügung, als ELT begann, sich als Alternative zum traditionellen ETL-Prozess zu etablieren (Ranjan, 2009; Davenport, 2009). Heutzutage hat jedoch nahezu jeder ETL-Anbieter auch ELT-Lösungen im Portfolio (Vassiliadis und Simitsis, 2009, S. 7).
Ein großer Vorteil der ELT-Technologie ist die bessere Hardwarenutzung im Vergleich zu ETL. Dadurch, dass die Transformation in der Zieldatenbank stattfindet, wird die Rechenleistung des Data Warehouse genutzt (Ranjan, 2009; Vassiliadis und Simitsis, 2009, S. 7; Davenport, 2009). Somit ist der ELT-Prozess durch Hardwareerweiterungen des Data Warehouse beliebig skalierbar und hängt nicht von der Rechenleistung der Staging Area ab (Vassiliadis und Simitsis, 2009).
Es bleibt jedoch festzuhalten, dass die Prozesse der Datenintegration häufig nicht einheitlich als ETL oder ELT betitelt werden. Überwiegend kommt der Begriff ETL zum Einsatz. Die konkrete Betitelung als ELT wird oft nur verwendet, wenn besonders hervorgehoben werden soll, dass der Transform-Prozess als letztes stattfindet. Außerdem existieren auch Mischformen aus beiden Möglichkeiten, beispielsweise ETLT (Vassiliadis, 2009). Hier finden einfache Schritte der Transformation vor dem Laden statt, während die rechenintensiven Transformationsvorgänge in der Zieldatenbank durchgeführt werden. Dies erschwert die Recherche deutlich, da für eine genaue Zuordnung zu ETL oder ELT die in einer Quelle genannte Prozessabfolge detailliert betrachtet werden muss. Allein anhand der Abkürzungen ETL oder ELT lässt sich deshalb keine genaue Einordnung vornehmen.
| Funktionsweise | Vorteile | Nachteile |
| Extraktion der Daten aus verschiedenen Quellen -> Laden aller Daten in die Zieldatenbank -> Transformation der Daten innerhalb der Zieldatenbank |
|
|
Streaming ETL
Der Data-Warehouse-Aktualisierungsprozess bei ETL findet üblicherweise in einem Zeitfenster mit geringer Auslastung statt, um den operativen Betrieb nicht zu stören und die relevante Rechenleistung zur Verfügung zu haben. Dies ist überwiegend nachts der Fall (Vassiliadis, 2009). Der ETL-Prozess wird überwiegend mit Batch-Verarbeitung durchgeführt. Das heißt, dass alle angefallenen Datensätze und Jobs automatisch sequentiell abgearbeitet werden (Lackes und Siepermann, 2018). Die Folge ist aber, dass die in der Zieldatenbank existenten Datensätze bis zu 24 Stunden alt sind. Die Aktualität der Daten ist somit für die Auswertung zeitlich kritischer Daten ungenügend. Diese Problematik kann durch die Unterteilung der großen Batches in kleinere Mini-Jobs, die beispielsweise stündlich durchgeführt werden, minimiert werden (Mukherjee und Kar, 2017). Dadurch können jedoch im operativen Betrieb kurze Ausfallzeiten entstehen. Eine weitere Methode, die die Aktualität der Daten in der Zieldatenbank deutlich verbessern kann, ist Change Data Capture (CDC) (Berkani und Bellatreche, 2018). Hier werden bei jedem Aktualisierungsprozess lediglich neue oder geänderte Daten extrahiert, transformiert und geladen (siehe Abbildung 3). Dadurch wird die Datenmenge deutlich reduziert und die Geschwindigkeit des Datenflusses deutlich erhöht. Die Latenzen können somit auf Minuten oder Sekunden reduziert werden (Biswas et al., 2019).
Abbildung 3: Schematische Darstellung des Streaming ELT-Prozesses nach Li und Mao (2015)
Dennoch kann hierbei nicht von Echtzeit gesprochen werden, da der Extraktionsprozess im Pull-Prinzip als Batch-Verarbeitung durchgeführt wird. Echtzeitbetrieb ist als Betriebsart definiert, bei der jeder Job unmittelbar nach dessen Auftreten abgearbeitet wird (Siepermann, 2018). Dies ist nur der Fall, wenn neue oder geänderte Daten den ETL-Prozess im Push-Verfahren durchlaufen. Dieser Vorgang wird als CDC-Trigger bezeichnet. Hier wird die Prozesskette nicht im Pull-Prinzip in einem gewissen Zeitintervall durchgeführt, sondern im Push-Verfahren immer dann, wenn neue oder geänderte Datensätze in den Quellen existieren. Der ETL-Prozess wird somit jeweils nur von sehr kleinen Datenpaketen durchlaufen, was eine sehr schnelle Abarbeitung ermöglicht (Berkani und Bellatreche, 2018; Mohammed Muddasir und Raghuveer, 2017; Biswas et al., 2019). Da der Prozess von den Datenquellen selbst getriggert wird, entspricht diese Vorgehensweise der Definition von Siepermann (2018) zufolge einem Echtzeitverfahren. In der Literatur wird diese Ausprägung des Datenintegrationsprozesses als Real-Time ETL oder Streaming ETL bezeichnet.
Hier ist es wichtig zu erwähnen, dass der Fokus dieser Bezeichnung auf Real-Time bzw. Streaming liegt. ETL wird in diesem Kontext erneut stellvertretend für den generellen Datenintegrationsprozess verwendet, unabhängig von der genauen Reihenfolge der Prozesse Extract, Transform und Load. Deshalb wird beispielsweise auch von ETL gesprochen, wenn die Transformation teilweise oder vollständig nach dem Laden in die Zieldatenbank stattfindet (Berkani und Bellatreche, 2018).
| Funktionsweise | Vorteile | Nachteile |
| Auftreten von neuen oder geänderten Datensätze triggert den Prozess -> Laden des Datensatzes in die Zieldatenbank -> Transformation des Datensatzes | · Daten sind in Echtzeit in der Zieldatenbank verfügbar
· Wegfall von großen Batch-Jobs |
· Unübersichtlicher Markt, da relativ neue Technik (siehe Tabelle 4) |
Tools zur Datenintegration
Im Folgenden soll ein Überblick über die aktuell gängigsten ETL- und ELT-Tools gegeben werden. Im aktuellsten Vergleich von ETL Tools werden die acht umsatzstärksten Produkte samt ihrer Stärken und Schwächen vorgestellt (Harvey, 2018). Diese Angaben werden im Folgenden mit Informationen aus den Artikeln von Mukherjee und Kar (2017) und Greengard (2018) ergänzt und systematisch in Tabellenform dargestellt. Dabei werden auch Informationen aus Datenblättern und Homepages der Produktanbieter verwendet.
In Tabelle 4 sind die Ergebnisse des Vergleichs übersichtlich dargestellt. Zu jedem Produkt wurden jeweils Stärken und Schwächen herausgearbeitet. Zudem wurde eine Zuordnung jedes Tools zum Prozess ETL oder ELT anhand der von den Quellen beschriebenen Prozessabfolge vorgenommen. Teilweise können die Tools auch beide Prozesse abbilden und sind deshalb entsprechend in der Tabelle doppelt zugeordnet. Das Tool „SAP Data Services“ konnte keinem der beiden Prozesse zugeordnet werden, da sich keine Informationen zum genauen Prozessablauf finden lassen (siehe Tabelle 4).
Als Fazit aus der in Tabelle 4 dargestellten Marktübersicht der gängigsten ETL- und ELT-Tools lässt sich festhalten, dass viele Anbieter den Prozess der Datenintegration unabhängig von der tatsächlichen Prozessreihenfolge als ETL bezeichnen. In vielen Fällen handelt es sich jedoch um ein ELT-Verfahren oder um eine hybride Mischform aus ETL und ELT. Hier bestätigt sich erneut die Erkenntnis, dass die Betitelung eines Datenintegrationsverfahrens als ETL oder ELT nicht zwangsweise mit der genauen Prozessreihenfolge zusammenhängt. Zudem lässt sich feststellen, dass alle Anbieter ihre Lösung im Paket mit Software und der benötigten Infrastruktur als Software-as-a-Service bereitstellen. Hier ermöglicht die Etablierung von Cloud-Speichern die Handhabung der ETL Prozesse über Weboberflächen. Dadurch entfällt für den Kunden die Anschaffung zusätzlicher Hardware. Zudem sind häufig vereinfachte Benutzeroberflächen vorzufinden, die die Gestaltung der Datenintegration ohne detallierte Programmierkenntnisse beispielsweise per Drag and Drop mit Hilfe vordefinierter Bausteine ermöglicht. Dadurch ist der komplette Prozess wesentlich flexibler und nicht, wie zu Beginn der ETL-Technik, starr definiert und nur schwer anzupassen.
| Anbieter | Produkt | Stärken | Schwächen | ETL | ELT | Sonstiges |
| Informatica | Data Integration Platform | Breites Produktspektrum (Harvey, 2018; Informatica GmbH, 2019) einfache Handhabung (Greengard, 2018) | Obere Preisklasse (Harvey, 2018) Funktionalitäten der einzelnen Produkte grenzen sich schlecht voneinander ab (Harvey, 2018) | x (Informatica GmbH, 2019) | x (Informatica GmbH, 2019) | CDC wird genutzt, dadurch Streaming-ETL möglich (Mukherjee und Kar, 2017) |
| Dell Boomi | Dell Boomi Platform | Benutzerfreundliche GUI (Greengard, 2018) vordefinierte Konnektoren (Boomi, 2018) | Standardoberfläche unterstützt nicht alle Funktionen, Erweiterung nur über Skripte möglich (Greengard, 2018) | x (Boomi, 2018) | Große Kundenbasis (Harvey, 2018) | |
| IBM | InfoSphere DataStage | Unterstützt auch stark heterogene Datenbasen (Greengard, 2018) Starke Skalierbarkeit durch das parallele Abarbeiten von Jobs (Mukherjee und Kar, 2017) | Verwirrende Preisgestaltung (Harvey, 2018) Edge-Funktionalitäten schwächer als im Vergleich zur Konkurrenz (Greengard, 2018) | x (IBM Corporation, 2016) | Streaming ETL durch CDC Capture möglich (Mukherjee und Kar, 2017) | |
| SAS | Data Management | Benutzerfreundliche GUI (Harvey, 2018) | Obere Preisklasse (Harvey, 2018) | x (SAS Institute Inc, 2017) | x (SAS Institute Inc, 2017) | Große Kundenbasis (Harvey, 2018) |
| SAP | Data Services | Besonders geeignet für den ETL-Prozess zwischen SAP ERP und SAP Hana (Harvey, 2018; SAP America, 2018) | Obere Preisklasse (Harvey, 2018) Schnittstellenprobleme mit anderen Anwendungen (Greengard, 2018) | Kostenabrechnung über die Anzahl der genutzten CPU Kerne (SAP America, 2018) | ||
| Oracle | Data Integration Platform Cloud | Untere Preisklasse (Mukherjee und Kar, 2017) Architektur ist für große Datenmengen geeignet (Greengard, 2018; ORACLE Deutschland B.V. & Co. KG, 2018) | Schlechte Dokumentation für das Fehlerhandling (Harvey, 2018; Greengard, 2018) | x (Mukherjee und Kar, 2017) | Verbesserung der Datenqualität durch Herausfiltern von schlechten Datensätzen vor dem Laden in die Zieldatenbank (Mukherjee und Kar, 2017) | |
| Talend | Data Management Platform | Untere Preisklasse (Harvey, 2018) unterstützt große Anzahl an Quellformaten | Teilweise Performanceprobleme (Greengard, 2018) | x (Talend Germany GmbH, 2019) | x (Talend Germany GmbH, 2019) | kostenlose Testversion verfügbar (Talend Germany GmbH, 2019) |
| Microsoft | Azure Data Factory | Untere Preisklasse (Harvey, 2018) vordefinierte Bausteine oder eigene Skripte möglich (Microsoft Corporation, 2019) einfache Integration mit Microsoft SQL Server Integration Services (SSIS) | Relativ unbekannt, da neu am Markt (Harvey, 2018) | x (Microsoft Corporation, 2019) | x (Microsoft Corporation, 2019) | Nutzungsbasierte Kostenabrechnung (hp) |
Im Rahmen dieser Recherche wurde ebenfalls eine Anfrage an die Hersteller der acht Tools in Tabelle 4 durchgeführt. In dieser Anfrage wurden die Hersteller im ersten Schritt gefragt, ob Sie ihr Produkt eher als ETL, ELT oder Hybridform einschätzen. In der zweiten Frage sollten die Hersteller begründen, in welchem der drei Prozesschritte Extract, Transform oder Load sie die Kernkompetenz ihres Produktes sehen. Eine Abgrenzung des Produktes zur Konkurrenz mit Begründung war Gegenstand der letzten Frage. Insgesamt beantworteten nur drei der Softwareantbieter die Fragen (siehe Anhang). Die Antworten sind jedoch nur eingeschränkt aussagekräftig, da beispielse alle drei Hersteller als Kernkompetenz Ihres Tools alle drei Prozessschritte Extract, Transform und Load angeben, obwohl nach einem einzigen Prozessschritt mit Begründung gefragt wurde. Auch gaben die drei Hersteller bei Frage eins mehrere Antworten, obwohl eine der drei Antwortmöglichkeiten ausgewählt und begründet werden sollte. Da nicht von allen Herstellern eine Antwort vorliegt und die drei beantworteten Fragebögen nicht aussagekräftig sind, lassen sich aus der Umfrage keine weitere Schlüsse ziehen. Die Informationen aus der Umfrage werden deshalb nicht in der Gegenüberstellung der acht Tools zur Datenintegration (siehe Tabelle 4) verwendet.
Zusammenfassung
In diesem Artikel wurden verschiedene Arten der Datenintegration wissenschaftlich aufgearbeitet und gegenübergestellt. Die beiden grundliegenden Verfahren ETL und ELT wurden samt ihren Vor- und Nachteilen vorgestellt. Zudem wurden die Techniken CDC und CDC-Trigger dargestellt, die den kompletten Prozess der Datenintegration in nahezu Echtzeit ermöglichen. Das letzte Element dieser Recherche war eine kurze Übersicht der gängigsten am Markt angebotenen ETL- und ELT-Tools.
Als Erkenntnis dieses Artikels lässt sich festhalten, dass die Data Warehouse Refreshment-Prozesse heutzutage nicht mehr ausschließlich nachts als große Batch-Jobs stattfinden. Die Vorgehensweise hat sich stark auf kleine Datenpakete fokussiert, die während dem laufenden Geschäftsbetrieb die Datenintegrationsprozesse durchlaufen. Dadurch ist es in der Praxis möglich, dem Endnutzer operative Daten aus verschiedensten Datenquellen in Echtzeit in Data Warehouses zu sammeln. Als weiterer Erkenntnisgewinn ist die oft fehlerhafte Bezeichnung den Datenintegrationsprozesses als ETL zu nennen. In der Praxis hat sich der Begriff ETL so stark etabliert, dass er häufig stellvertretend für den generellen Datenintegrationsprozess verwendet wird. Dabei wird die genaue Abfolge der einzelnen Prozessschritte jedoch außer Acht gelassen. Deshalb können allein anhand der Betitelung als ETL oder ELT keine Rückschlüsse auf die technische Abfolge der Datenintegration gemacht werden. Deshalb muss bei einer Recherche in diesem Themenbereich immer die genaue Prozessabfolge untersucht werden, um eine Technologie aus technischer Sicht korrekt als ETL oder ELT bezeichnen zu können.
Die Gegenüberstellung der ETL-Tools baut lediglich auf literarischen Quellen und Herstellerangaben auf. Um eine detallierte Betrachtung der ETL-Tools auf der Basis von Erfahrungswerten durchzuführen, muss jedes Tool individuell getestet werden. Nur so können die Stärken und Schwächen in der Praxis evaluiert werden.
Literaturverzeichnis
Bansal, S.K. und Kagemann, S. (2015), „Integrating Big Data: A Semantic Extract-Transform-Load Framework”, Computer, Jg. 48 Nr. 3, S. 42–50.
Berkani, N. und Bellatreche, L. (2018), „Streaming ETL in Polystore Era”, in Vaidya, J. und Li, J. (Hrsg.), Algorithms and architectures for parallel processing: 18th International Conference, ICA3PP 2018, Guangzhou, China, November 15-17, 2018, proceedings, LNCS sublibrary: SL1 – Theoretical computer science and general issues, Bd. 11336, Springer, Cham, Switzerland, S. 560–574.
Biswas, N., Sarkar, A. und Mondal, K.C. (2019), „Efficient incremental loading in ETL processing for real-time data integration”, Innovations in Systems and Software Engineering, Jg. 5 Nr. 3, S. 1.
Boomi, I. (2018), „Dell Boomi Datasheet”, [online] verfügbar unter: https://boomi.com/wp-content/uploads/Dell-Boomi-Integration-Datasheet.pdf (zugegriffen am 02.07.2019).
Buxmann, P., Hess, T. und Lehmann, S. (2008), „Software as a Service”, WIRTSCHAFTSINFORMATIK, Jg. 50 Nr. 6, S. 500–503.
Davenport, R. (2009), „ETL vs ELT. A Subjective View”, [online] verfügbar unter: https://pdfs.semanticscholar.org/1d9e/7bf640c94f4014247d6a1dc46a5af5e79d5e.pdf.
Gour, V., Sarangdevot, S.S., Tanwar, G.S. und Sharma, A. (2010), „Improve Performance of Extract, Transform and Load (ETL) in Data Warehouse”, International Journal on Computer Science and Engineering, Jg. 2 Nr. 3, S. 786–789.
Greengard, S. (2018), „Top 10 Data Integration Tools”, [online] verfügbar unter: https://www.datamation.com/big-data/top-data-integration-tools.html (zugegriffen am 15.07.2019).
Harvey, C. (2018), „Top 8 ETL Tools”, [online] verfügbar unter: https://www.datamation.com/big-data/top-8-etl-tools.html (zugegriffen am 15.07.2019).
Hoisl, B. (2019), „Grundlagen des Digital Mindset”, in Hoisl, B. (Hrsg.), Produkte digital-first denken: Wie Unternehmen software-basierte Produktinnovation erfolgreich gestalten, Springer Gabler, Wiesbaden, S. 93–123.
IBM Corporation (2016), „Flexible integration Flexible Integration with IBM InfoSphere DataStage V11.5”, [online] verfügbar unter: https://www.ibm.com/downloads/cas/5QV1WDAY (zugegriffen am 08.07.2019).
Informatica GmbH (2019), „Homepage”, [online] verfügbar unter: https://www.informatica.com/de/products/data-integration.html (zugegriffen am 02.07.2019).
Lackes, R. und Siepermann, M. (2018), „Stapelbetrieb – Ausführliche Definition”, [online] verfügbar unter: https://wirtschaftslexikon.gabler.de/definition/stapelbetrieb-43352/version-266683 (zugegriffen am 03.06.2019).
Li, X. und Mao, Y. (2015), „Real-Time data ETL framework for big real-time data analysis”, in 2015 IEEE International Conference on Information and Automation: In conjunction with 2015 IEEE International Conference on Automation and Logistics conference program digest August 8-10, 2015, the old town of Lijiang, Yunnan, China, Lijiang, China, 8/8/2015 – 8/10/2015, IEEE, Piscataway, NJ, S. 1289–1294.
Liao, W.-H., Chen, P.-W. und Kuai, S.-C. (2017), „A Resource Provision Strategy for Software-as-a-Service in Cloud Computing”, Procedia Computer Science, Jg. 110, S. 94–101.
Microsoft Corporation (2019), „Data Factory”, [online] verfügbar unter: https://azure.microsoft.com/de-de/services/data-factory/ (zugegriffen am 15.07.2019).
Mohammed Muddasir, N. und Raghuveer, K. (2017), „CDC and Union based near real time ETL”, in Technologies, I.C.o.E.C.a.I. (Hrsg.), 2017 2nd International Conference on Emerging Computation and Information Technologies (ICECIT): 15-16 Dec. 2017, Tumakuru, 12/15/2017 – 12/16/2017, IEEE, [Piscataway, NJ], S. 1–5.
Mukherjee, R. und Kar, P. (2017), „A Comparative Review of Data Warehousing ETL Tools with New Trends and Industry Insight”, in Padma Sai, Y., Garg, D. und Conference, I.I.A.C. (Hrsg.), 7th IEEE International Advanced Computing Conference: IACC 2017 5-7 January 2017, VNR Vignana Jyothi Institute of Engineering and Technology, Hyderabad, Telangana, India proceedings, Hyderabad, India, 1/5/2017 – 1/7/2017, IEEE, Piscataway, NJ, S. 943–948.
ORACLE Deutschland B.V. & Co. KG (2018), „Experience Powerful Data Integration in the Cloud”, [online] verfügbar unter: https://cloud.oracle.com/opc/paas/ebooks/Oracle_Data_Integration_Platform_Cloud.pdf (zugegriffen am 02.07.2019).
Ranjan, V. (2009), „A Comparative Study between ETL (Extract-Transform-Load) and E-LT (ExtractLoad-Transform) approach for loading data into a Data Warehouse”, [online] verfügbar unter: https://pdfs.semanticscholar.org/b6aa/6cd1aec2c36c8d7e573b109a8d1d2e87b593.pdf.
Sabtu, A., Azmi, N.F.M., Sjarif, N.N.A., Ismail, S.A., Yusop, O.M., Sarkan, H. und Chuprat, S. (2017), „The challenges of Extract, Transform and Loading (ETL) system implementation for near real-time environment”, in Systems, I.C.o.R.a.I.I. in (Hrsg.), Social transformation through data science: ICRIIS 2017 5th International Conference on Research and Innovation in Information Systems Adya Hotel, Langkawi, Kedah, 16-17th July 2017, Langkawi, Malaysia, 7/16/2017 – 7/17/2017, IEEE, Piscataway, NJ, S. 1–5.
SAP America, I. (2018), „Enterprise Data Management Software”, [online] verfügbar unter: https://www.sap.com/products/data-services.html#product-overview (zugegriffen am 02.07.2019).
SAS Institute Inc (2017), „SAS Data Management Fact Sheet”, [online] verfügbar unter: https://www.sas.com/content/dam/SAS/en_us/doc/factsheet/sas-data-management-102451.pdf (zugegriffen am 08.07.2019).
Siepermann, M. (2018), „Echtzeitbetrieb – Ausführliche Definition”, [online] verfügbar unter: https://wirtschaftslexikon.gabler.de/definition/echtzeitbetrieb-34713/version-258211 (zugegriffen am 17.06.2019).
Stephanidis, C., Mellin, J., Berndtsson, M., Berndtsson, J.M.M., Veijalainen, J., Jensen, E.C., Beitzel, S.M., Frieder, O., Schweikardt, N., Amsler, R.A., Shabo, A., Aref, W.G., Allen, R.B., Zhang, E., Zhang, Y., Cudré-Mauroux, P., Dong, G., Li, J., Zhou, Z.-H., Wong, J., Tompa, F.W., Flurry, G., Gerstley, L., Song, I.-Y., Chen, P.P., Fagin, R., O’Neil, P., Carroll, M., Pehcevski, J., Piwowarski, B., Zhou, J., Hong, M., Demers, A., Gehrke, J., Riedewald, M., Sharon, G., Etzion, O., Chandy, K.M., Ericsson, A., Jensen, C.S., Snodgrass, R.T., Wasserkrug, S., Niblett, P., Ammon, R. von, Shapiro, M., Kemme, B., Weiner, M., Peleg, M., Hardavellas, N., Pandis, I., Hinterberger, H., Libkin, L., Thalheim, B., Chrysanthis, P.K., Ramamritham, K., Zhang, D., Manolopoulos, Y., Theodoridis, Y., Tsotras, V.J., Vassiliadis, P. und Simitsis, A. (2009), „Extraction, Transformation, and Loading”, in ÖZSU, M.T. und LIU, L. (Hrsg.), Encyclopedia of database systems, Springer, New York, London, S. 1095–1101.
Talend Germany GmbH (2019), „Data Integration Technische Details”, [online] verfügbar unter: https://de.talend.com/products/specifications-data-integration/ (zugegriffen am 09.07.2019).
Vaisman, A. und Zimányi, E. (2014), „New Data Warehouse Technologies”, in Vaisman, A. und Zimányi, E. (Hrsg.), Data Warehouse Systems, Springer Berlin Heidelberg, Berlin, Heidelberg, S. 507–537.
Vassiliadis, P. (2009), „A Survey of Extract–Transform–Load Technology”, International Journal of Data Warehousing and Mining, Jg. 5 Nr. 3, S. 1–27.
Vassiliadis, P. und Simitsis, A. (2009), „Near Real Time ETL”, in Kozielski, S. und Wrembel, R. (Hrsg.), New trends in data warehousing and data analysis, Annals of Information Systems, Bd. 3, Springer, [New York], S. 1–31.
Wibowo, A. (2015), „Problems and available solutions on the stage of Extract, Transform, and Loading in near real-time data warehousing (a literature study)”, in 2015 International Seminar on Intelligent Technology and Its Applications (ISITIA): Proceeding Surabaya, Indonesia, 20-21 May 2015, Surabaya, Indonesia, 5/20/2015 – 5/21/2015, IEEE, [Piscataway, New Jersey], S. 345–350.
Andreas Ott
- Studentischer Mitarbeiter im Forschungsprojekt OBerA an der FHWS
- Student im Masterstudiengang Wirtschaftsingenieurwesen