
Auswertung vorhandener Sensordaten mit MatLab
17.11.2020
1. Einleitung
Im Rahmen des Projektes „Optimierung von Prozessen und Werkzeugmaschinen durch Bereitstellung, Analyse und Soll-Ist-Vergleich von Produktionsdaten“ (OBerA) der Hochschule Würzburg-Schweinfurt wurden Sensordaten einer CNC-Maschine eines mittelständischen Komponentenherstellers erhoben. Mithilfe von Machine-Learning Algorithmen und der Software MatLab soll auf aufgrund dieser Daten eine automatische Rüstzeiterkennung erfolgen.
Die Daten werden in einer MySQL Datenbank gespeichert und mithilfe von MySQL-Workbench exportiert. Anschließend werden die Daten mit Excel vorverarbeitet und in MatLab importiert. Dort kommt die App „Classification Learner“ zum Einsatz, um einen geeigneten ML-Algorithmus zu ermitteln und die Rüstzeiten zu identifizieren.
2. Export aus Datenbank
Um eine Auswertung zu ermöglichen, werden die benötigten Sensordaten mithilfe der Software MySQL Workbench 8.0 abgefragt und im CSV-Format exportiert. So sind analog zu Abbildung 1 diverse SQL-Abfrage durchzuführen (Schritt 1) und anschließend die abgefragten Daten zu exportieren (Schritt 2).
Die hierfür verwendete SQL-Abfrage lautet:
SELECT * FROM obera.SenseTest WHERE TOPIC LIKE ‚%wago%‘ AND CAST(TIMESTAMP AS datetime) between ‚2020-10-20 13:00:00‘ and ‚2020-10-20 23:00:00‘;

Abbildung 1: Exportieren der Daten in MySQL-Workbench
Der Vorgang ist insgesamt mit den folgenden Sensoren zu wiederholen:
- ‚%wago%‘
- ‚%O5D150%‘
- ‚%Velleman1%‘
- ‚%Velleman2%‘
- ‚%keyence%‘
Als Ergebnis wird somit je Sensor eine CSV-Dateien generiert (Abbildung 2).

Abbildung 2: Sensordaten in Form mehrerer CSV-Dateien
Treten bei der SQL-Abfrage Probleme auf, könnte folgendes Vorgehen Abhilfe schaffen:
Menü „Edit“ öffnen und „Preferences“ auswählen:
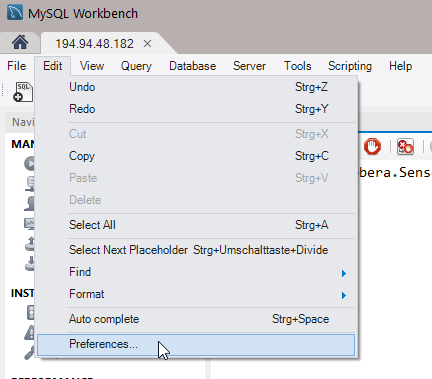
Abbildung 3: „Edit“-Schaltfläche in mySQL
Anschließend sind unter „SQL-Editor“ folgende Einstellungen anzuwenden und mit „OK“ zu bestätigen:

Abbildung 4: Das Übernehmen der hier gezeigten Einstellungen hinsichtlich der „DBMS-Connection“ kann der Lösung von Abfrageproblemen helfen
3. Vorverarbeitung der Daten
Um eine Auswertung zu ermöglichen, sind die Daten in die Form eines sogenannten „Analytics-Base-Table“ (ATB) zu bringen. Hierbei entspricht eine Zeile einem Timestamp (TS), welcher alle zu diesem Zeitpunkt vorhandenen Sensorwerte abbildet (Tabelle 2).
| ID | TIMESTAMP | TOPIC | PAYLOAD | UNIT | SENSOR | Derived Value |
Derived ValueDesc |
| 39429753 | 2020-10-20T12:59:59.508 | FHWS/OBerA/Velleman2 | 0 | digital | velleman HAA27 | 0 | Tuer zu |
| 39429754 | 2020-10-20T13:00:00.334 | FHWS/OBerA/ifm/ifm-O5D150 | 020.625 |
cm | ifm O5D150 | 0 | Tuer zu |
| 39429755 | 2020-10-20T13:00:00.334 | FHWS/OBerA/ifm/Keyence-FD-Q20C | 0 | L/min | Keyence FD-Q20C | 0 | Durchfluss nein |
| 39429756 | 2020-10-20T13:00:00.348 | FHWS/OBerA/Wago-855-9150 | 6034.14 | W | Wago 855-9150/2000-0701 | 1 | Produktion ja |
| 39429757 | 2020-10-20T13:00:00.686 | FHWS/OBerA/Velleman1 | 1 | digital | velleman HAA27 | 1 | Tuer offen |
| 39429758 | 2020-10-20T13:00:00.712 | FHWS/OBerA/Velleman2 | 0 | digital | velleman HAA27 | 0 | Tuer zu |
| 39429759 | 2020-10-20T13:00:01.334 | FHWS/OBerA/ifm/ifm-O5D150 | 200.625 | cm | ifm O5D150 | 0 | Tuer zu |
Um die Umwandlung der Daten in diese Form zu ermöglichen, sind entsprechende Schritte zur Datenvorverarbeitung anzuwenden.
Als problematisch erweist sich, dass pro Zeitstempeln vereinzelt Sensorwerte fehlen. Grund hierfür ist, dass die Daten aufgrund von Verzögerungen nicht exakt im Sekundentakt in die Datenbank gespeichert werden. Folglich weisen bestimmte Sensordaten doppelte Werte pro Timestamp auf bzw. überspringen diesen vollständig.
Mithilfe einer Excel-Datei werden die bereits generierten CSV-Dateien in die Form eines ATB umgewandelt. Das Zielformat der Daten ist in Tabelle 2 ersichtlich.
| ID | TS | VM1 | VM2 | Abstand | KM | L | Status |
| 1 | 13:00:00 | 1 | 0 | 20 | 0 | 6034 | Rüsten |
| 2 | 13:00:01 | 1 | 0 | 20 | 0 | 6043 | Rüsten |
| 4 | 13:00:03 | 1 | 0 | 20 | 0 | 6078 | Rüsten |
| 5 | 13:00:04 | 1 | 0 | 20 | 0 | 6082 | Rüsten |
| 6 | 13:00:05 | 1 | 0 | 20 | 0 | 6090 | Rüsten |
| 7 | 13:00:06 | 1 | 0 | 20 | 0 | 6091 | Rüsten |
| 8 | 13:00:07 | 1 | 0 | 20 | 0 | 6098 | Produktion |
| 11 | 13:00:10 | 1 | 0 | 20 | 0 | 6102 | Produktion |
| 12 | 13:00:11 | 1 | 0 | 20 | 0 | 6112 | Produktion |
| 13 | 13:00:12 | 1 | 0 | 20 | 0 | 6075 | Produktion |
Den Datensätzen werden schließlich in einer weiteren Spalte die Eigenschaften „Rüsten“ bzw. „Leerlauf/Produktion“ zugeordnet und die vorverarbeiteten Daten in einem neu erstellten MatLab-Projekt importiert.
4. Import der Daten in MatLab
Zu Beginn sind die Daten in MatLab zu impotieren (Abbildung 2).

Abbildung 5: Button für den Import von Daten in MatLab
Anschließend werden die entsprechenden Datentypen der Spalten festgelegt (Abbildung 3).
- ID = Number
- TS (Timestamp) = Datetime
- TI (Tür innen) = Categorical
- TT (Tür Maschinentisch) = Categorical
- KM (Kühlmittel) = Number
- L (Leistung) = Number
- Status = Categorical
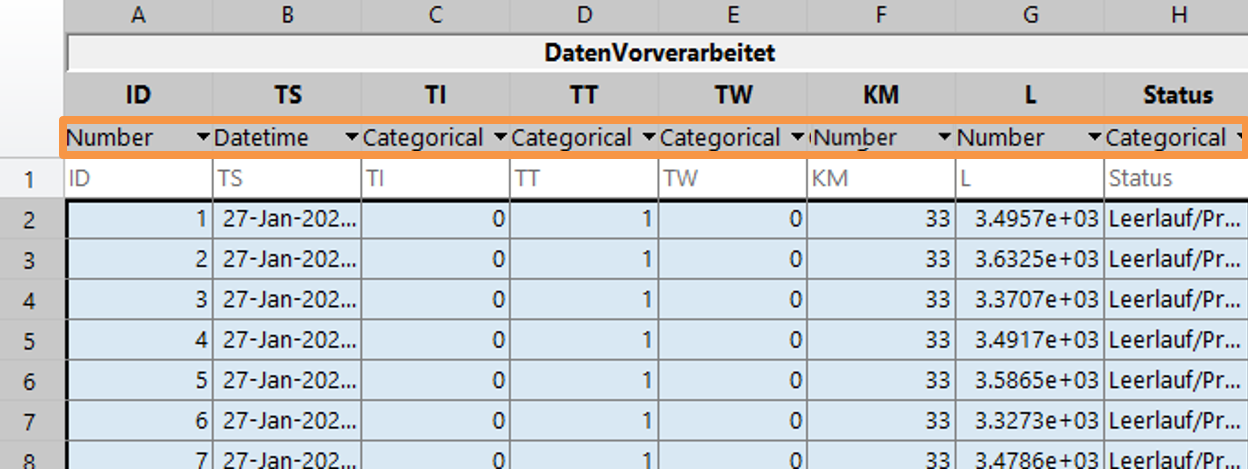
Abbildung 6: Festlegung der Datentypen
Nach dem Import der Daten ist das GUI „Classification Learner“ unter dem Register „Apps“ zu öffnen (Abbildung 4).

Abbildung 7: Öffnen der App „Classification Learner“
Nach der Auswahl des bereits importierten Datensets müssen die Response- und Vorhersagevariablen festgelegt werden (Abbildung 5). Hierbei wird der Status (Rüsten/Produktion) als Response-Variable festgelegt. ID, Timestamp (TS) und Status eigenen sich nicht als Vorhersagevariablen und werden deshalb abgewählt. Als Validationsverfahren zeigte sich die Cross-Validation als erfolgreich gegen das Problem des overfittings.

Abbildung 8: Auswahl der Response- und Vorhersagevariablen
In der App „Classification Learner“ können nun Algorithmen zum Trainieren des Modells ausgewählt werden. Mit der Voreinstellung „All-Quick-To-Learn“ werden automatisch ausgewählte Algorithmen trainiert. Die Auswahl des gewünschten Algorithmus ist mit dem Button „Train“ zu bestätigen (Abbildung 6).

Abbildung 9: Auswahl der Testalgorithmen
Nun wird das Modell automatisch trainiert und die allgemeine Genauigkeit des Algorithmus ermittelt (Abbildung 7). In diesem Anwendungsfall wurden alle verfügbaren Trainingsmechanismen getestet, wobei sich die Methode „Fine Tree“ mit 92,8% als genauesten Algorithmus erweist (Abbildung 7).

Abbildung 10: Allgemeine Genauigkeit ausgewählter Algorithmen
5. Evaluation der Algorithmen
Neben der in der Ansicht aller trainierten Algorithmen angezeigter Genauigkeiten (Abbildung 10) sind die Algorithmen weiter zu untersuchen – beispielsweise mithilfe einer Confusion-Matrix. Hierzu muss unter der Registerkarte „Plots“ die „Confusion Matrix“ ausgewählt werden (Abbildung 10).

Abbildung 10: Auswahl der „Confusion Matrix“ in der Registerkarte „Plots“
Es zeigt sich, dass der Algorithmus „Fine Tree“ zwar die höchste allgemeine Genauigkeit besitzt, aber den Rüstvorgang lediglich zu 51,7% korrekt vorhersagt (Abbildung 11).

Abbildung 11: Confusion Matrix des Fine Tree Algorithmus
Hingegen dazu weißt der Algorithmus RUS Bossted Tree eine geringe allgemeine Genaugikeit an, ist aber besser in der Lage Rüstvorgänge zu identifizieren. In diesem Anwendungsfall gelang es dem Algorithmus in 88,4% der Fälle den Rüstvorgang korrekt zu identifizieren.

Abbildung 12: Confusion Matrix des RUS Boosted Tree Algorithmus
Es reicht folglich nicht, lediglich die von MatLab angezeigte allgemeine Genauigkeit bei der Wahl des Algorithmus zu berücksichtigen.
6. Trainingsmodell auf Testdaten Anwenden
Um das Trainingsmodell auf einen Nicht-Klassifizierten Datensatz anzuwenden, ist das geeignetste Modell zu Exportieren (Abbildung 13).

Abbildung 13: Trainiertes Modell exportieren
Nun Testdaten mit der leeren Spalte „Rüststatus“ importieren – Analog zu Abbildung 5 und Abbildung 6.
Zur Vorhersage in die Eingabemaske von MatLab folgende Formel eingeben:
yfit = trainedModel.predictFcn(T)
trainedModel = Name des exportieren, trainierten Modells
T = importierter Testdatensatz
Um eine Ansicht des Entscheidungsbaumes zu erzeugen, kann folgende Formel verwendet werden:
view(trainedModel.ClassificationTree,’mode‘,’graph‘)
Simon Schmitt
- Studentischer Mitarbeiter im Forschungsprojekt OBerA an der FHWS
- Student im Masterstudiengang Wirtschaftsingenieurwesen
